

Business Intelligence & Analytics
Cleanlab’s AI automatically detects incorrect values and other issues lurking in your dataset (outliers, near duplicates, low-quality examples, non-IID sampling, etc). This includes errors in associated metadata (e.g. annotations or tags for images/documents).

Case StudyEstimating Wake-Word False Accept Rates of Smart Speaker
· Google used Cleanlab to estimate how often its assistant devices mis-respond to the wake-word “Hey Google”.
· Amazon used Cleanlab to estimate how often its assistant devices mis-respond to the wake-word “Alexa”.
· These estimation problems are challenging due to incomplete data and erroneous labels. Learn more.

Case StudyE-commerce Analytics
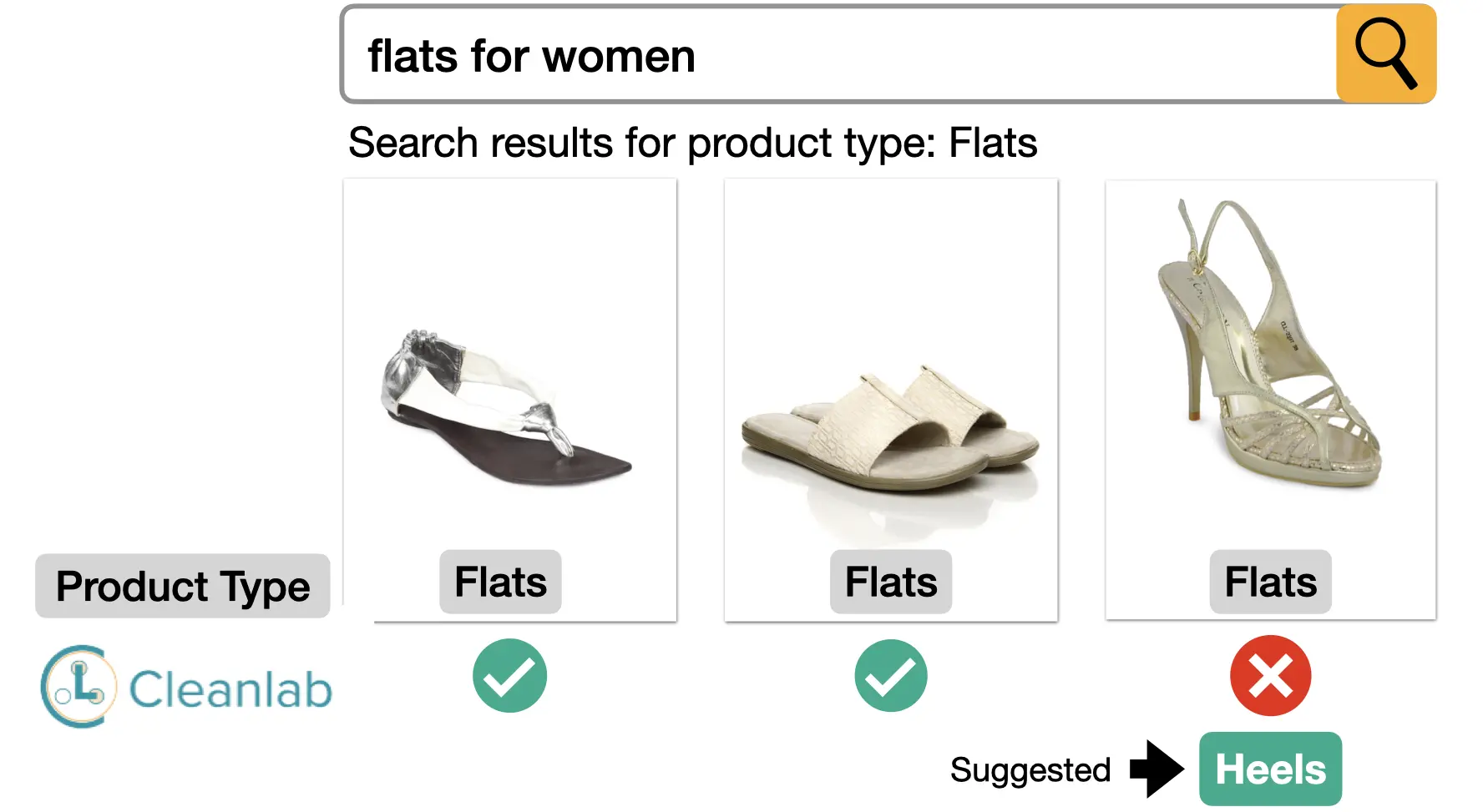
HOW CLEANLAB CAN IMPROVE YOUR DATA ANALYSIS
Videos on using Cleanlab Studio to find and fix incorrect values in:
Summarize overall patterns in data errors to better understand where they stem from and how they might affect conclusions.
Audit data stored in many file formats: Excel, CSV, JSON, etc. including data with many raw text fields or images.
Automatically discover outliers (anomalies) which may have an outsized impact on data-driven conclusions and should be handled with care. Read more.
Automatically detect violations of key statistical assumptions like IID-sampling, e.g. if the data are drifting over time. Such violations may invalidate many data-driven conclusions. Read more.
Effectively analyze crowdsourced datasets in a robust manner, and estimate which examples require additional review and which annotators are best/worst overall. Read more.
Use Cleanlab AutoML to train and deploy state-of-the-art ML models in 1-click. Robustly train models on cleaned data to predict any information recorded in your dataset, no Machine Learning expertise required! This can help with missing value imputation and other tasks involving incomplete information.
Read about ensuring high quality evaluation data for LLM prompt selection.
Read about automatic error detection for multi-label data (e.g. image/document tagging).
Read about errors in famous datasets detected with Cleablab Studio.
Related applications
Foundation and Large Language Models
Boost fine-tuning accuracy and reduce time spent

Data Annotation & Crowdsourcing
Label data efficiently and accurately, understand annotator quality.
Data Entry, Management, and Curation
AI expert review of your data stores to find errors or incorrect labels.
Customer Service
Produce better data/models faster for customer support, customer segmentation, ...
Content Moderation
Train more accurate content moderation models in less time.