

Improving Legal Judgement Prediction with Cleanlab Studio
 Hui Wen Goh
Hui Wen Goh
This article demonstrates how easily one can use Cleanlab Studio to automatically improve the accuracy of a legal judgement prediction model. Like any real-world dataset, large legal datasets contain issues that can be addressed to improve the accuracy of any model trained on that data. Finding and fixing these issues can be a tedious task, but we demonstrate a fully automated solution to obtain top-quality data and an improved model using AI.

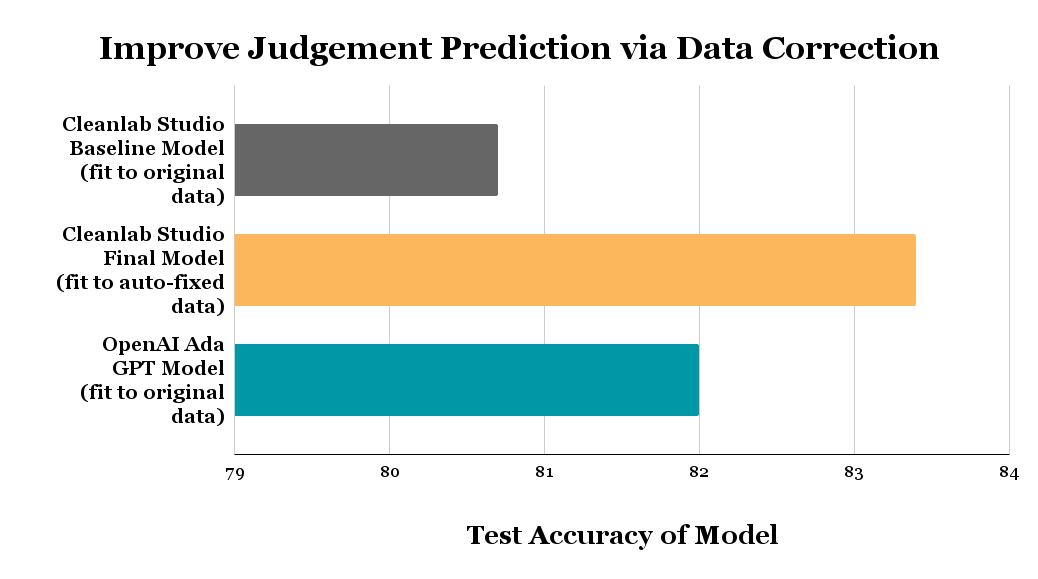
The above figure shows the judgement prediction accuracy on court cases in a held-out test set achieved by 3 models: a fine-tuned OpenAI Large Language Model, a baseline model fit via a few clicks in Cleanlab Studio, and a final version of this Cleanlab Studio model fit to an auto-corrected version of the same dataset (all data correction was done automatically in just a few clicks).
Background
With advances in Machine Learning like Large Language Models (LLMs), the legal sector is being transformed through automation of labor-intensive tasks such as document/contract reviews, legal text processing, and more. Legal judgement prediction is a fundamental task that can greatly assist many legal practitioners if done accurately. In legal judgement prediction, ML models predict the outcome of a court case given a text description of information relevant to the case. Lawyers can use these predictions to estimate the likelihood of winning a case, or the probability of a successful appeal, which can help with strategy and decision-making.
These judgement prediction models are often trained on large amounts of existing legal data. However real-world legal data is messy and full of issues that may adversely impact the training of ML models, making their predictions less reliable. In high-stakes legal applications, an incorrect prediction can greatly harm all parties involved – hence it’s crucial that we try to curate the best quality data for training the most reliable prediction model possible.
European Court of Human Rights Dataset
Here, we take a look at a legal judgement prediction dataset of cases from the European Court of Human Rights (ECHR). Each entry in this dataset contains text describing information of the case in court, and our goal is to predict whether or not a given case involves a violation of any human rights article. These case texts are too lengthy to display in full, so let’s take a look at some key points from some cases that were ruled as human rights violations or not.
Here’s a snippet from a case labeled as violating a human rights article. These sentences highlight potential human rights violations, such as physical assault, verbal abuse, and the use of excessive force by police officers.
The applicant was born in 1986 and lives in Pskov … At about 2 a.m. on 17 August 2005 the applicant was travelling in a car with B. – who was driving – M. and T. Their car was stopped by the police. Police Officers F. and K. asked for their ID cards … F. and K. had demanded that he stand facing a wall, hands raised, and had searched him. They had allegedly insulted him verbally and physically. In particular, they had punched him repeatedly in the face and the lumbar region and had tried to knock him down …
On the other hand, this other case below that focuses on a financial advisory dispute is labeled as not violating any human rights.
HME is a small family company founded in 1970. It provides independent financial advice … the company was approached by L, a pilot who was soon to reach the company retirement age … He sought HME’s advice about his pension arrangements … L filed a complaint with the Financial Ombudsman Service (FOS) on 11 November 2003, alleging that HME had given him inappropriate advice regarding his pension … The complaint was considered by an FOS adjudicator, who communicated his opinion on it in a letter to HME dated 7 April 2004 … He concluded that the transfer and investment funds recommended to L may have been unsuitable …
Using Cleanlab Studio to Identify Potential Errors in the European Court of Human Rights Dataset
We upload this dataset to Cleanlab Studio and with a few button clicks, Cleanlab will automatically identify any potential label errors in our dataset. In addition to estimating overall dataset quality, Cleanlab Studio shows us the most severely mislabeled court cases first, so we can prioritize which data needs correction and further review.
Here is an example (court case) from the dataset that has been incorrectly labeled as False (ie. not a human rights violation), but Cleanlab has identified that it actually appears mislabeled and it should probably be marked as True instead.

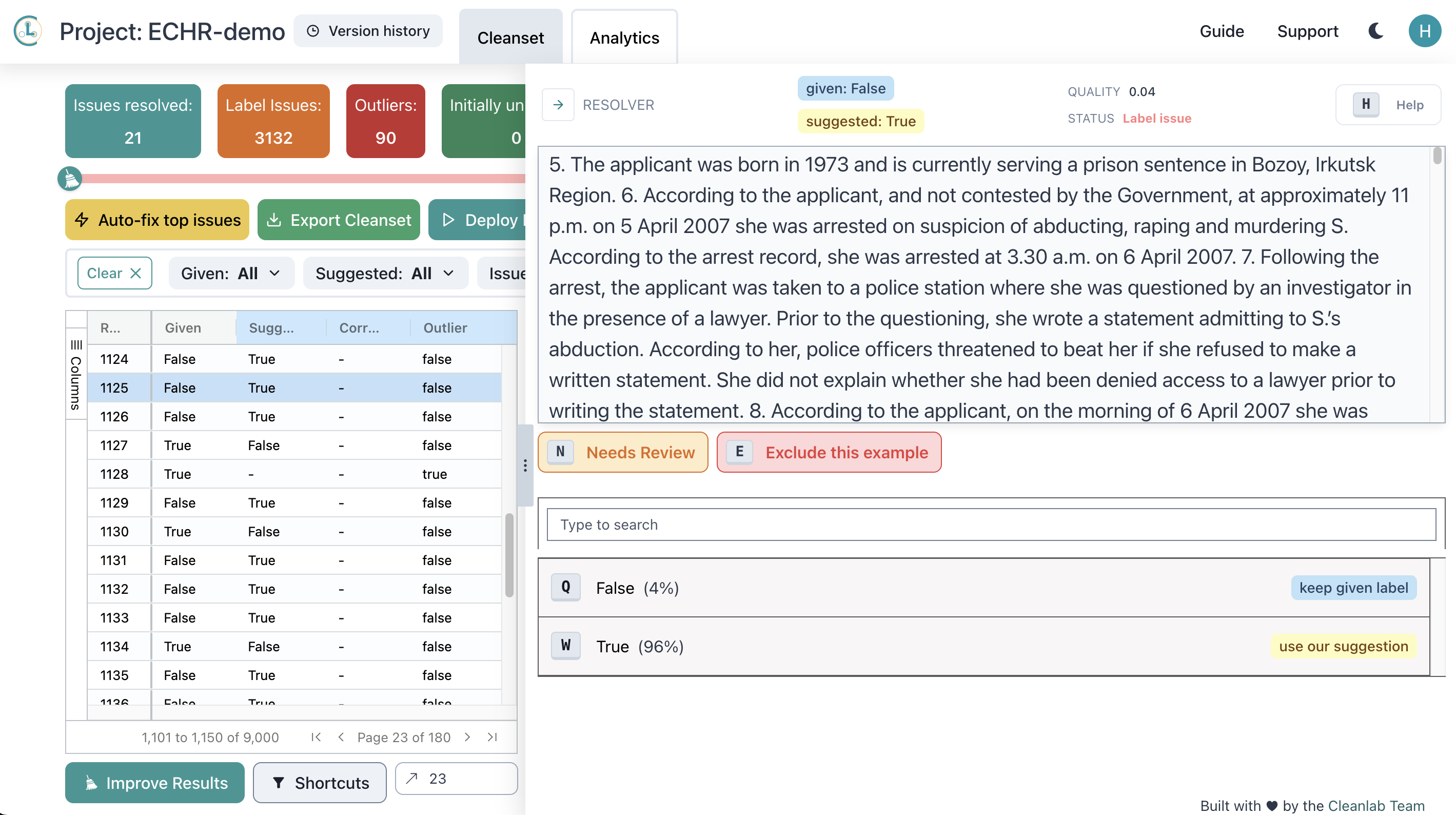
Here are some excerpts from the case text that informs us that this should be labeled as a violation:
- “According to her, police officers threatened to beat her if she refused to make a written statement.”
- “They hit her on the head and threatened to rape her, and then handcuffed her and pushed her to the floor.”
- “They punched her in the solar plexus and the stomach, and pulled her by the legs. They attached a wire to her right leg and placed a metal object between her shoulders, then subjected her to electrocution while gagging her mouth to muffle her screams.”
Cleanlab Studio automatically identified this error in the dataset, and provides a simple interface to quickly correct it. The AI powering this application can automatically detect many different types of data issues, which you can efficiently resolve via the intuitive interface.
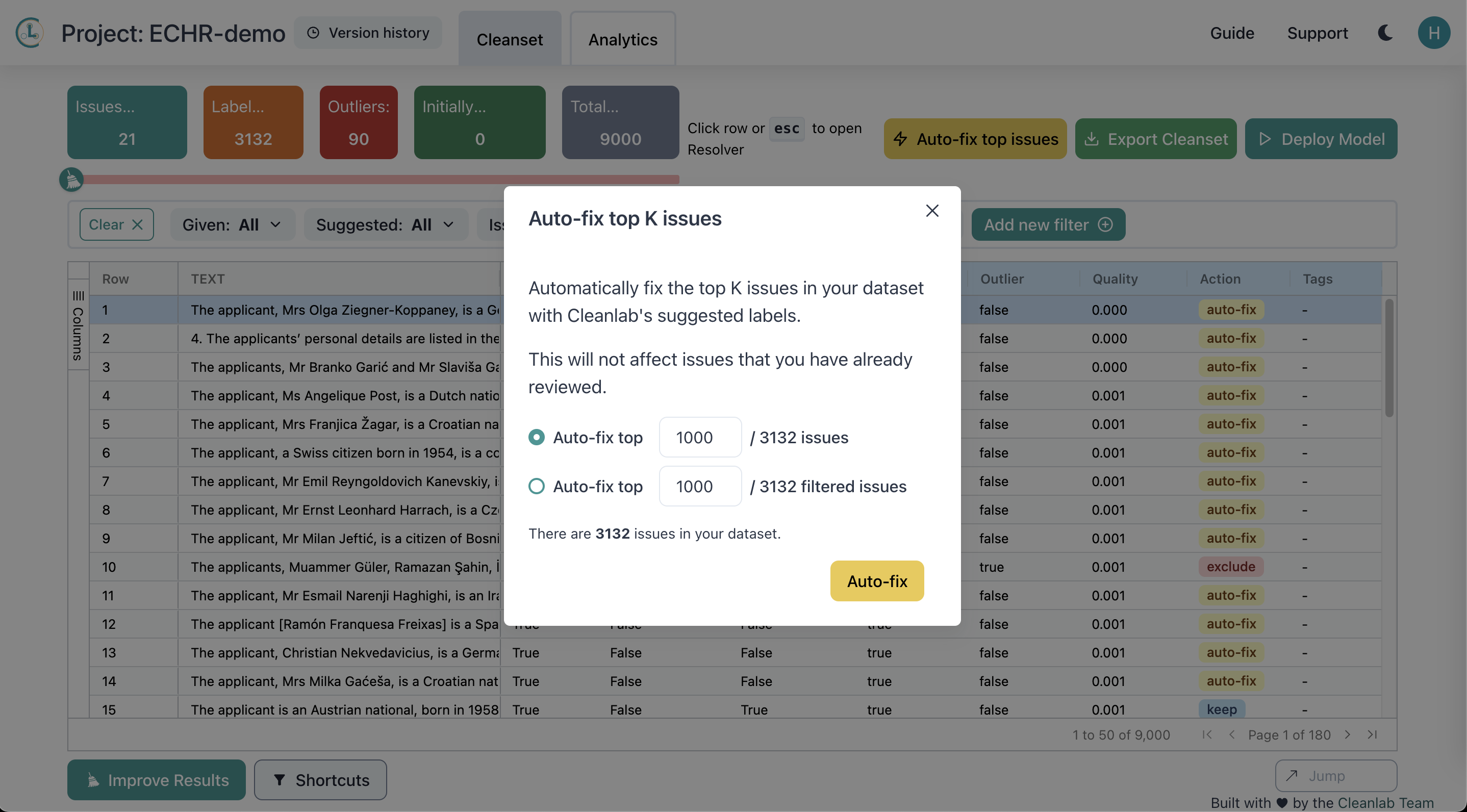
Cleanlab Studio offers a feature to speed up the data correction process: the ability to auto-fix the top identified data issues for which the AI is most confident about a suggested fix. While manually inspecting each flagged example in the dataset ensures you can achieve the highest quality version of your dataset, this is tedious, especially when some court case text has hundreds of words. Rather than manually inspecting all detected issues, we simply used this auto-fix feature to automatically correct the most likely mislabeled court-cases to an alternative automatically-suggested label inferred to be more appropriate by Cleanlab Studio. With a few clicks, we managed to correct hundreds of data issues, saving tons of time!

Deploy Models for Prediction in Cleanlab Studio
After reviewing the erroneous datapoints flagged by Cleanlab Studio and correcting them, you can now train a new model on this corrected data to make predictions for future court cases. Producing a cleaner training dataset allows you to produce an improved model that provides more reliable predictions going forward.

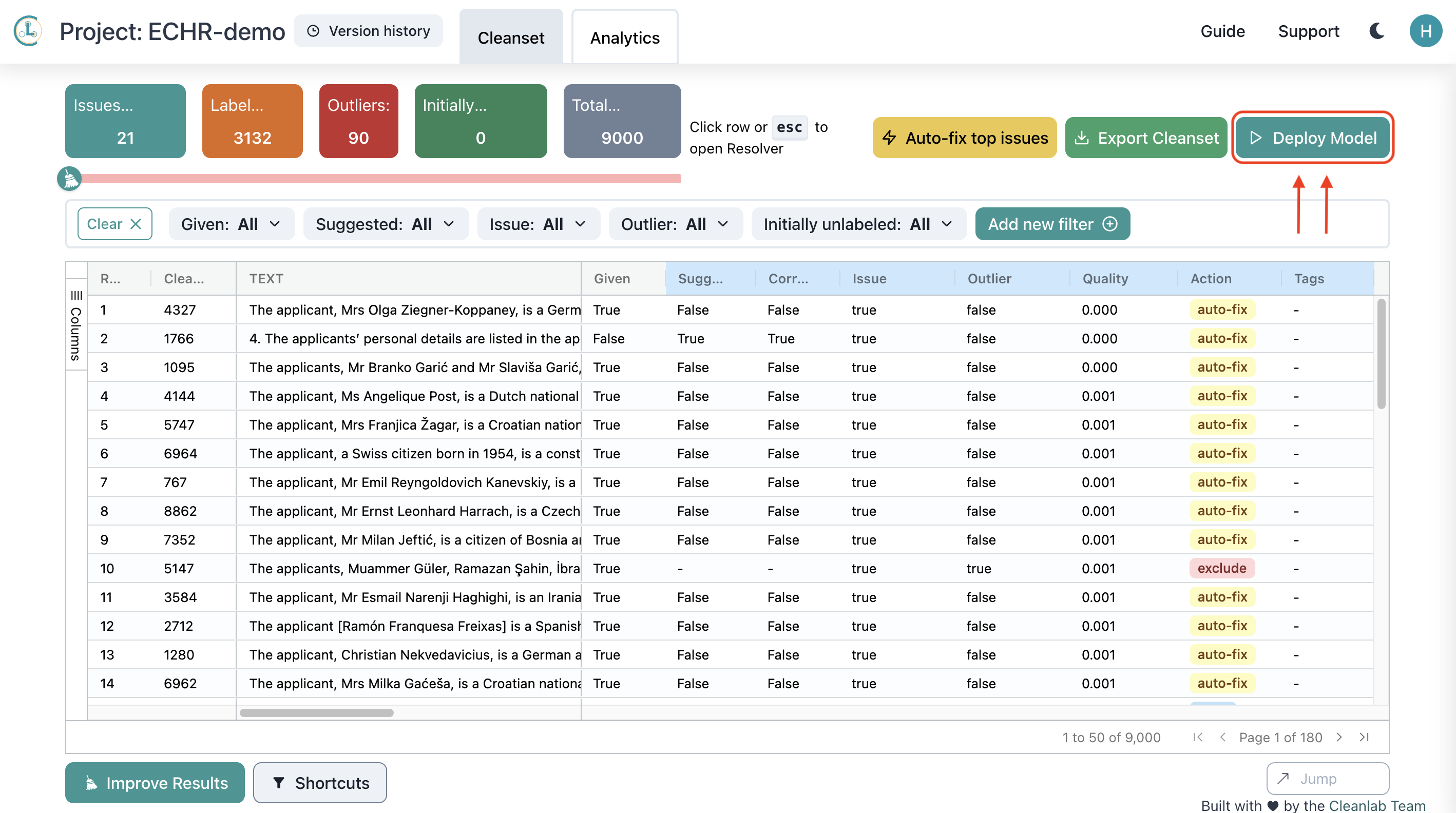
With just one click, Cleanlab Studio will automatically retrain a model using the corrected data and deploy it for you. In the future, you can easily upload new data, and Cleanlab Studio will return predictions almost instantaneously.

When the prediction is complete, we can download the CSV file that contains the model predictions for the new datapoints.

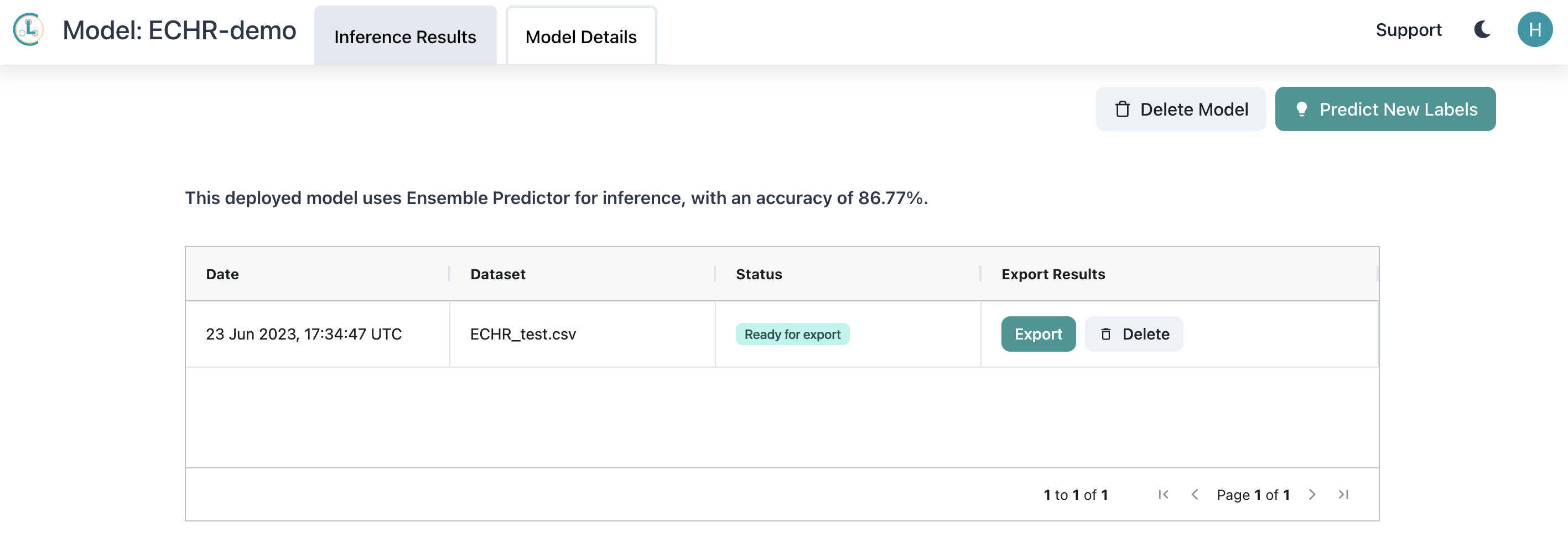
This entire process to go from raw, messy legal data to a reliably deployed judgement prediction model took only a few clicks to: upload the raw training data, automatically detect issues in the data via a baseline model, correct these issues, and the retrain + deploy a final model, which can produce judgment predictions for new court cases with just a couple more clicks. Who says deploying Machine Learning / AI is complicated?
Evaluating the Predictions
We’ve seen how easily Machine Learning and data improvement workflows are done in Cleanlab Studio, but how good are the results? Let’s first see if correcting our data improved the judgement prediction model. In this application, we measure the accuracy of our deployed model on a held-out test set containing approximately 2500 new court cases. These examples in the test set have been separately examined to ensure that they are annotated in a trustworthy manner and will provide an accurate evaluation of model predictions.
The original baseline model Cleanlab Studio initially trained on the noisy raw data achieved a test accuracy of 80.8%. This baseline model is the one Cleanlab Studio uses to auto-detect issues in your dataset, which you can correct, such that a better final model can be trained on the corrected dataset. After correcting erroneous labels flagged by Cleanlab Studio, the subsequently-trained final model achieved a test accuracy of 83.4%. By improving the dataset in an algorithmic manner, we managed to obtain a 14% error reduction on the model predictions – all with just a few clicks!
To compare against the state-of-the-art for handling such text data, we fine-tuned an OpenAI ada Large Language Model on the original data as a Judgment classifier. Fine-tuning LLMs allows them to produce far more accurate predictions for domain-specific datasets. For this legal prediction task, the fine-tuned OpenAI model only obtained a test accuracy of 82%. Thus on real-world data, you can get better ML performance with a few clicks in Cleanlab Studio (couple clicks to upload data, 1 click to train baseline model, 1 click to detect issues, 1 click to auto-fix the detected issues, 1 click to retrain and deploy final model) than with OpenAI LLMs – which require writing code and learning their APIs. Models deployed with Cleanlab Studio are not only more accurate/reliable, but also much smaller (and hence able to return predictions quickly and at low costs).
These results highlight that once you achieve good quality data, even smaller (easier to deploy) models can provide reliable predictions for your applications.
Automated Data-Centric AI tools such as Cleanlab Studio help us efficiently conduct tedious tasks such as finding and fixing data and label issues that can be used to improve any ML model. Such tools are useful across many applications beyond this legal judgement prediction task, and they can handle arbitrary text datasets as well as data from tables/spreadsheets/databases and data containing images.
Resources
- Easily improve your data and models with Cleanlab Studio!
- Follow us on LinkedIn or Twitter to stay up-to-date on the best data quality tools.