

The Future of Relevance Determination: Leveraging AI for Enhanced E-Discovery
 Chris Mauck
Chris Mauck
Successful litigation hinges on identifying the relevant data for legal actions through processes like e-discovery and relevance determination. However, the effectiveness of these processes is inevitably compromised by mistakes like incorrect labeling and misinterpretation when just relying on human annotators like busy paralegals and lawyers. Maintaining impartial and accurate categorization of evidence and data sources is often hard and can be extremely expensive, in some cases millions of dollars per day. This post introduces Cleanlab Studio, an AI solution for automatic document review that autonomously detects mis-categorized legal documents enhancing the accuracy of relevance determination.


Above is a collection of labeled document excerpts that contain a few issues that paralegals overlooked when annotating relevance determinations. Cleanlab Studio automatically detects these annotation errors and suggests a better categorization for each example.
Background
E-discovery (electronic discovery) involves locating, identifying, securing, and producing electronically stored information (ESI) in response to a legal or investigative process. Relevance determination, meanwhile, is a key facet of e-discovery, which entails assessing the importance or pertinence of a particular piece of data within a specific context.
Despite the advances in e-discovery processes, the potential for human error remains a significant obstacle. Misclassification, incorrect labeling, and misinterpretation are all factors that could lead to significant inaccuracies. In fact, these issues can often escalate to the point where they undermine the whole purpose of e-discovery and relevance determination, leading to improper decision-making and wasted resources.
Another facet that is important to consider is the importance for no bias to be present in the human workers who decide whether or not certain documents fit in certain categories. The beneficial aspect of using modeling for these tasks is to ensure that all documents are categorized by the same, non-changing criteria. This ultimately leads to better compliance as you can ensure an unbiased categorization from the start.
Let’s take a look at how Cleanlab Studio — a no-code, automated AI tool can automatically identify mis-categorized legal documents and provide more accurate relevance determination.
E-Discovery Data
A typical e-discovery text dataset can be broadly categorized into three labels: relevant, not-relevant, and privileged. ‘Relevant’ documents contain information directly pertinent to a case or investigation. ‘Not-relevant’ data, as the name suggests, holds no bearing on the matter at hand. Finally, ‘privileged’ documents are sensitive and protected by privacy laws, often containing confidential communication between parties like attorneys and their clients, or personal information like social security, credit card, and bank account numbers.

Here we study this e-discovery dataset that contains text examples and their given labels like those listed above. For privacy reasons all of the sensitive information and the text itself has been synthetically generated to resemble real e-discovery data.
Within moments, Cleanlab Studio was able to automatically find:
- over 50 mis-categorized examples (~10% of the dataset)
- 40 (near) duplicate examples
- 6 possibly ambiguous examples
Here’s a few of the top mislabeled examples:
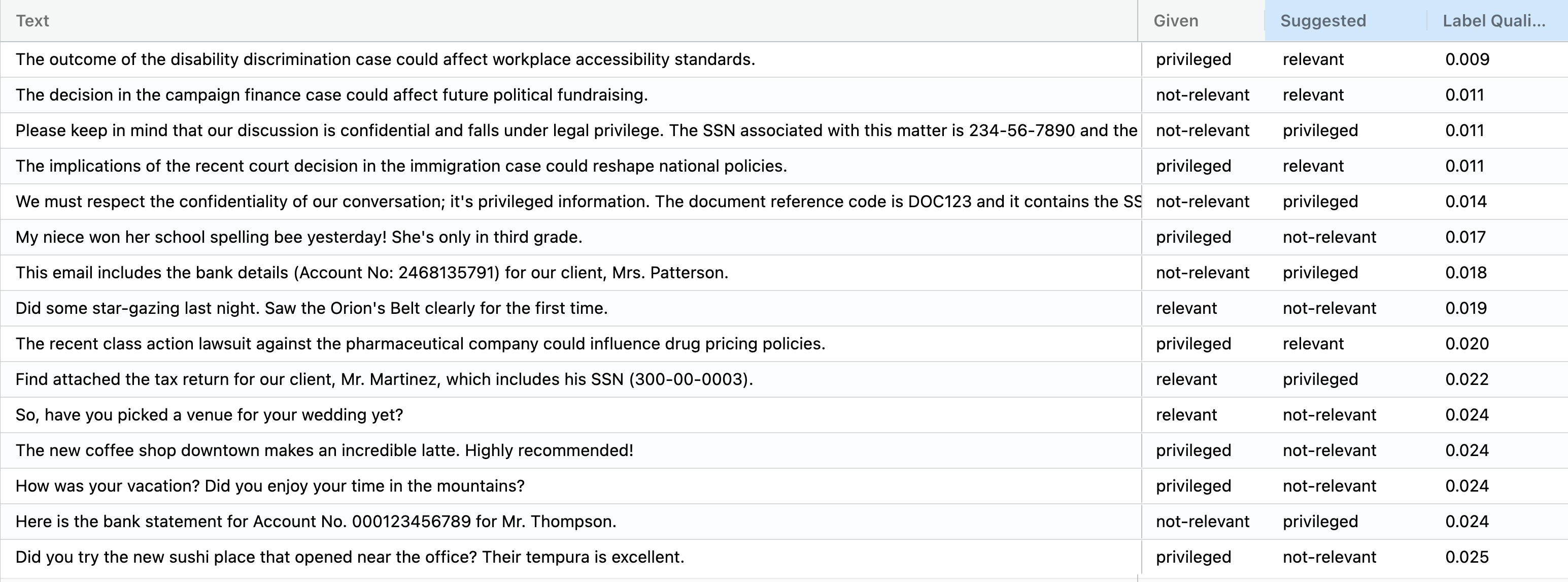
Without the automated data validation from Cleanlab Studio, these errors could have gone unnoticed. In the case that some examples didn’t have annotations, you would be able to select them and annotate them manually. The remainder of this blog will aim to walk you through all of the steps required to get the same results for yourself.
Using Cleanlab Studio
It only takes a few clicks for you to improve your data and train more robust models with Cleanlab Studio.
Upload
Simply drag and drop the dataset into the Studio interface or you can browse and select from your files. After a few clicks you’re ready to create a project.
Create a Project
Once the dataset is uploaded to the app, you have a few options to choose from: the name of your project, which columns to include, and which model type to use (fast for speed and regular for performance).
Finding and Correcting Issues
Once the model training concludes, you can access the automated corrections computed by Cleanlab Studio by clicking “Ready for Review”. Here we show correcting a few examples that were mis-categorized and replacing the label with the Cleanlab suggested label.
In the interface you the ability to analyze:
- mislabeled examples (e.g. labeled as
relevantbut should beprivileged) - outliers (e.g. text that shouldn’t be included at all)
- ambiguous examples (e.g. borderline cases that need further domain knowledge to categorize)
- near duplicates (e.g. if examples are included more than once or slight variations)
To assist with inspection, Cleanlab Studio offers you other useful features like:
- Analytics — click the tab at the top to see charts and graphics that help you understand what’s happening (good or bad) in your data
- Filters — the filter bar allows you to use the insights gained in the analytics page and segment your data for more efficient and directed correction
- Auto-Fix — if you find that you want to correct the annotations of many examples at a time, you can use auto-fix to change the label to the Cleanlab suggested label for as many examples as you’d like — all with just one click!
Closer Inspection
The complex nature of legal documents inevitably makes manual indexing prone to issues. In most legal settings this type of manual work is outsourced to paralegals that are tasked with searching through thousands of electronic records. You can easily imagine how mentally taxing this work is and see how records can easily be marked as the wrong category.

Above we see the top 10 examples that Cleanlab Studio has indicated as problematic. Let’s take a look at row 2 which reads:
Text: The decision in the campaign finance case could affect future political fundraising.
Given Label: not-relevant
Cleanlab Suggested Label: relevant
This is clearly an example of a mis-categorized record that is common because paralegals often overlook relevant evidence when tasked with reviewing a mountain of documents. Cleanlab Studio automatically detected that the label of not-relevant was incorrect and also suggested the correct label of relevant. In this dataset, Cleanlab Studio found that about 10% of the records were categorized incorrectly.
Model Deployment
In certain cases, many additional documents might be collected over time, and you might want to use Machine Learning to automatically categorize them for efficiency. With one click in Cleanlab Studio, you can train many ML models and automatically select and deploy the best model to make predictions for the incoming data.
Applying Cleanlab Studio: A Case Study
Having seen how Cleanlab Studio works, let’s delve into its real-world application. The tool was recently put to the test by the data science team of a company with several thousand employees during the e-discovery phase of actual legal proceedings.
Their aim was to identify errors in relevance annotations for documents. In this context, an audit using error-estimation software was considered vital for compliance reasons and to maintain objectivity. The software in question was based on published research with theoretical justifications.
The results were revealing. Cleanlab Studio automatically identified a vast number of essential documents that paralegals had inadvertently failed to mark as relevant. It further showed that relevance-prediction models trained within its framework were 15% more accurate than the customer’s existing models. Comparable benefits were also noted with regards to annotations for privileged content.
Following these successful findings, the customer now uses Cleanlab Studio for every legal case. In their words:
I rely on you guys to be my level of scrutiny.
Using Cleanlab in litigation discovery, we can accomplish with 5 lawyers what previously required 50 lawyers.
This case study underscores the transformative power of AI in the realm of legal discovery. It proves that Cleanlab Studio not only improves data accuracy but also enhances efficiency, allowing legal teams to work smarter, not harder.
Next Steps
- Ensure proper legal document categorization with Cleanlab Studio!
- Join our Community Slack to discuss using AI in legal applications and automated data validation.
- Follow us on LinkedIn or Twitter for updates on new techniques to ensure the highest quality data.