

Automatic Error Detection for Image/Text Tagging and Multi-label Datasets
 Aditya Thyagarajan
Aditya Thyagarajan  Elías Snorrason
Elías Snorrason  Curtis Northcutt
Curtis Northcutt  Jonas Mueller
Jonas Mueller
Image/document tagging represent important instances of multi-label classification tasks. While each example is labeled with exactly one of K classes in standard multi-class classification, each example can belong to multiple (or none) of the K classes in multi-label classification. For instance in the CelebA dataset, an image of a person may be tagged as both Wearing Hat and Wearing Earrings rather than these classes being mutually exclusive. Because annotating such data requires many decisions per example, multi-label classification datasets often contain tons of label errors, which harm the performance of ML models.
We’ve just published new research on algorithms to detect incorrect annotations in any multi-label classification dataset. You can run our algorithms on your own data via the open-source cleanlab package by following this 5min tutorial. Running cleanlab’s find_label_issues() method on CelebA reveals around 30,000 mislabeled images in the dataset!

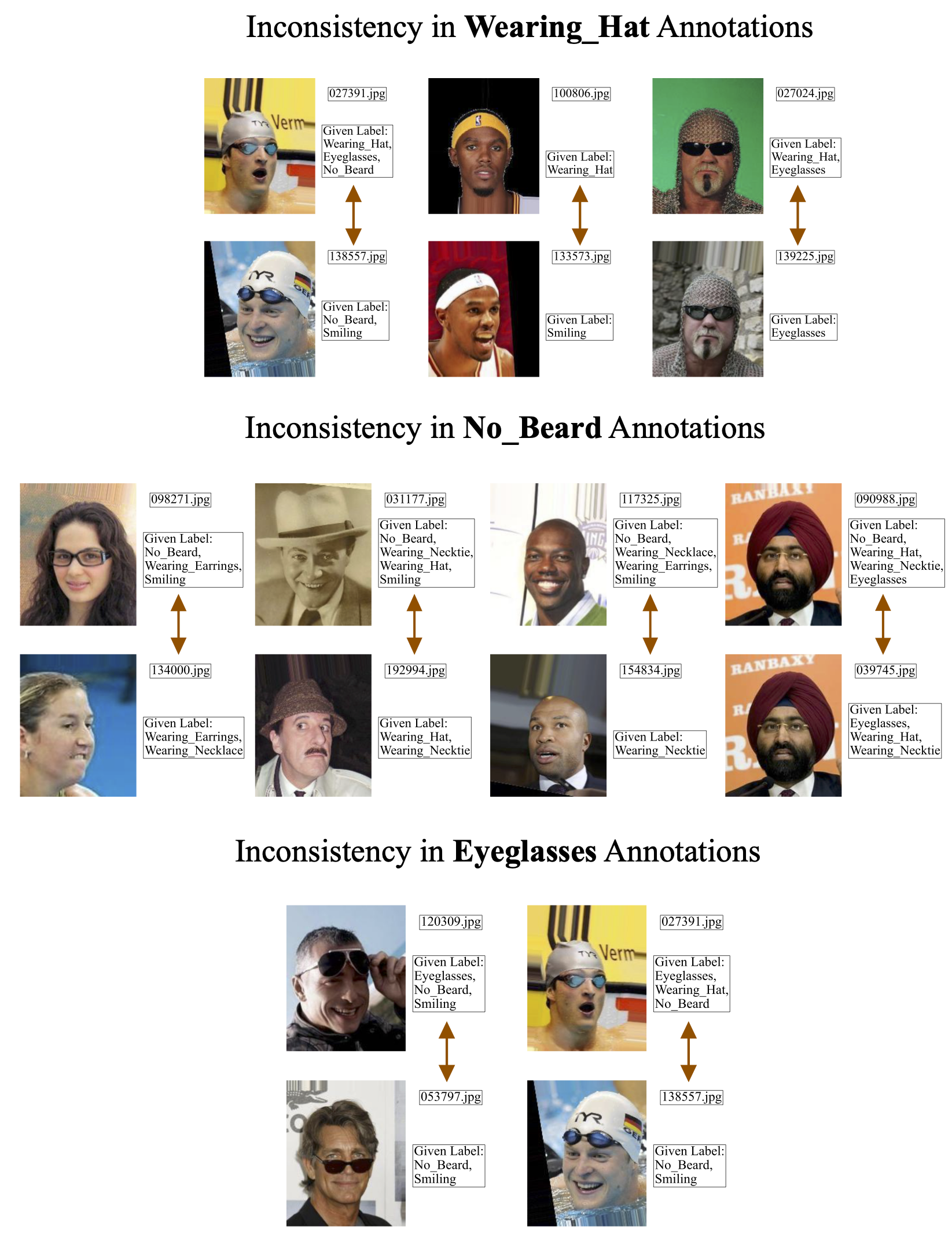
Above we show examples of inconsistency in annotations for Wearing Hat, No Beard, or Eyeglasses tags in CelebA. Note how for each pair of similar images, one of these tags (e.g. Wearing Hat) is annotated for one image but not the other, so one of their labels is clearly incorrect. We immediately discovered these inconsistencies by looking at the top few images our algorithm ranked most likely to have a label error. These examples are a small subset of the many issues in these tags that we observed throughout the CelebA dataset.
Algorithms to detect errors in multi-label data
The cleanlab.multilabel_classification module offers two approaches to identify label issues in multi-label data: multilabel_classification.filter.find_label_issues and multilabel_classification.rank.get_label_quality_scores.
One is a multi-label extension of Confident Learning to estimate which examples are mislabeled in the dataset. The second approach estimates a numeric label quality score (between 0 and 1) for each example in the dataset, such that examples whose label likely contains an error receive lower scores.
find_label_issues is useful to estimate the number and identity of mislabeled examples in the dataset, while get_label_quality_scores ranks every example in your multi-label dataset so you can prioritize which examples to re-examine under a limited label verification budget.
Refer to the paper for technical details.
Both approaches operate on the predicted class probabilities from any multi-label classifier model, regardless of how it was trained. Following the model-agnostic spirit of data-centric AI, cleanlab can be used with any existing (or future) model to efficiently find and fix errors in its training set, in order to subsequently train a better model. Additionally, cleanlab can find and clean errors in your test set for benchmarking, reduce the number of annotations you need, and many other data-centric tasks.
Introducing the EMA label quality score
To produce a label quality score for a particular example, cleanlab computes an exponential moving average (EMA) over the model’s self-confidences for every tag/annotation given to the example. The score heavily emphasizes the class annotations the classifier model is highly confident are incorrect while being less influenced by the other class annotations for this example. This is desirable because model-estimated confidence values exhibit nuisance variation even for correct class annotations. The resulting EMA label quality score is robust to inaccuracies in model predicted probaiblities.
Efficacy of Cleanlab multi-label algorithms
Below we show 15 of the top-50 images with the lowest estimated label quality scores in CelebA, computed by applying cleanlab to predictions from a Pytorch multi-output neural network classifier that we fine-tuned from TIMM. Here we choose not to show many additional flagged label errors related to incorrect annotation of the No Beard tag amongst these top-50 images, in order to highlight diverse label errors in this dataset automatically detected by cleanlab.
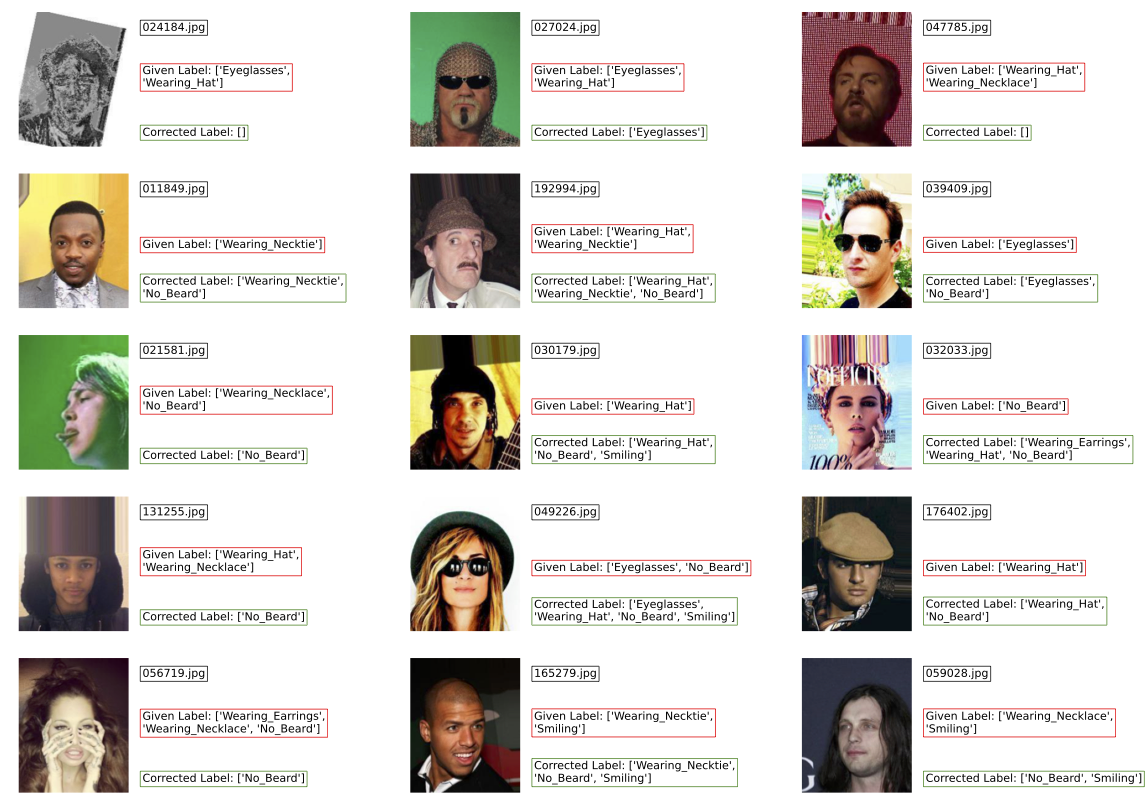
There are both extraneously added tags as well as many missing tags in the dataset. Inspecting the full set of label issues estimated by cleanlab, we see that the No Beard tag is erroneously missing from many images where it should apply, presumably because many annotators forgot about this tag. Inspecting the top 100 images ranked by our algorithm as well as 100 random images, we find that mislabeled images are 4.5 times more prevalent among the set prioiritized by cleanlab compared to the overall dataset.
Additional Benchmarks
We also benchmark our EMA label quality score against 9 other approaches to detect mislabeled examples. We consider two groups of 10 datasets (Large vs. Small) which differ in the number of examples and classes, as well as the degree of label noise. Since the underlying true labels are known for each dataset, we evaluate different label quality scores based on their Average Precision (AP) @ T for detecting which examples contain any error in their annotated label. Below we show the results setting T equal to the true number of mislabeled examples in each dataset, and running cleanlab twice on each dataset with predictions from a Logistic Regression model and from a Random Forest.
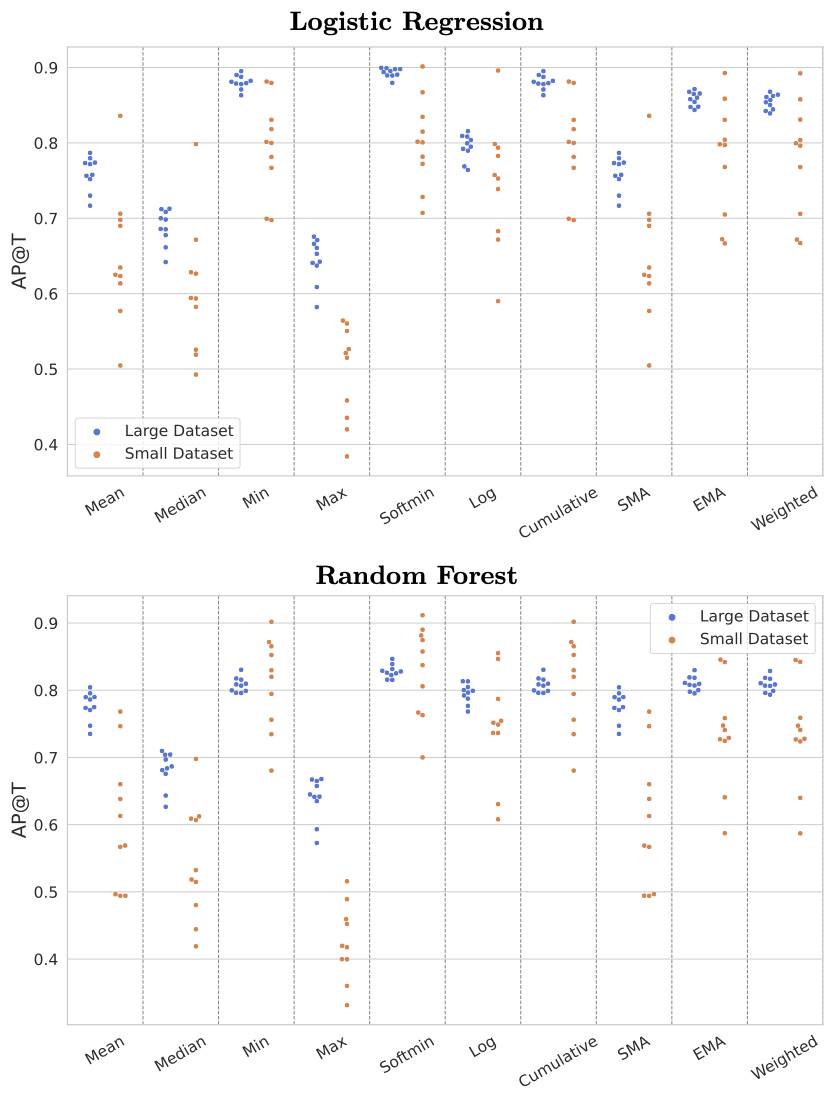
An effective label quality score should both detect examples with any error in their given label and prioritize severely mislabeled examples with at least two errors in their given label. For instance, images whose annotated set of tags contains two or more differences from the true set of tags that should actually apply, are more detrimental in the training set of a ML model than images whose annotated tags are only one-off from the ground truth set. Below we show the Average Precision (AP) @ T for detecting such severely mislabeled examples, setting T equal to the true number of examples with at least two errors in each dataset.
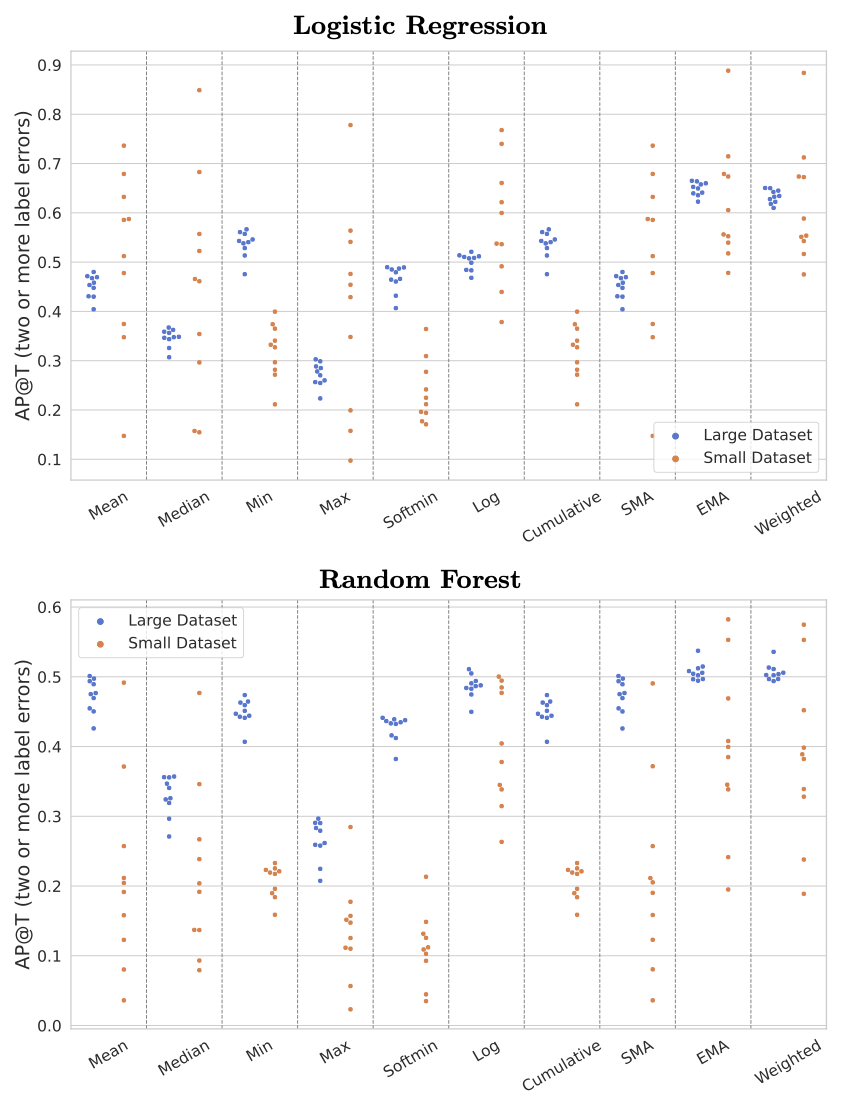
These results illustrate that cleanlab’s EMA score is effective for both detecting mislabeled examples with any error in their annotation as well as those which are severely mislabeled. The results hold across multiple datasets and ML models, demonstrating the general utility of our proposed label quality score. Refer to our paper and benchmarking code for details and other evaluations we performed. An effective label quality score helps you identify the annotation errors your data far more efficiently than random inspection!
Show me the Code
After training a (multi-output) classifier on your dataset, use it to produce predicted class probabilites for each example. Ideally these predictions should be out-of-sample, e.g. produced via cross-validation. Then you can find which examples in the dataset have label issues via a single line of code:
from cleanlab.multilabel_classification.filter import find_label_issues
ranked_label_issues = find_label_issues(
labels=labels,
pred_probs=pred_probs, # predicted class probabilities from model
return_indices_ranked_by="self_confidence",
)where for a 3-class multi-label dataset with 4 examples, we might have say:
labels = [[0], [0, 1], [0, 2], [1]]
pred_probs = np.array(
[[0.9, 0.1, 0.1],
[0.9, 0.1, 0.8],
[0.9, 0.1, 0.6],
[0.2, 0.8, 0.3]]
)For the best results, train your classifier to properly account for correlations between the classes’ rather than in a one-vs-rest manner. We have an example notebook demonstrating how to train a Pytorch neural network in this way. Modeling classes’ co-occurrence often improves the accuracy of a multi-label classifier and cleanlab works better with a more accurate classifier.
Resources to learn more
- Quickstart Tutorial: quickly find annotation errors in your own image/text tagging and multi-label classification datasets.
- Example Notebook: shows how to use cleanlab to discover thousands of label errors in the CelebA image tagging dataset.
- Model-Training Example: shows how to train a state-of-the-art Pytorch neural network for multi-label classification on any image dataset.
- Paper: describes our algorithms in detail and presents extensive benchmarks showing why the code in cleanlab outperforms alternative approaches to detect annotation errors in multi-label classification data.
- Code to reproduce our benchmarks: evaluates many different algorithms for detecting errors in multi-label data.
While cleanlab helps you automatically find data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a (very cool) no-code platform. Export your corrected dataset in a single click to train better ML models on better data. Try Cleanlab Studio at https://app.cleanlab.ai/.
Join our community of scientists and engineers to discuss the future of open-source Data-Centric AI: Cleanlab Slack Community
Documentation | Blogs | Research Publications | Visualizing Confident Learning
Contributors
A big thank you to the data-centric jedi who contributed code for cleanlab v2.2 (especially the newest contributors listed first): Ilnar, Chris Mauck, Luna Köpke, Aditya Thyagarajan, Mohit Saxena, Huan Tran, Jonas Mueller, Anish Athalye, Ulyana Tkachenko, Elías Snorrason, Curtis Northcutt, Hui Wen Goh.
Special thanks to Po-He Tseng for helping with early tests of our improved multi-label algorithms and the research behind developing them. We also thank the individuals who contributed bug reports or feature requests.
If you’re interested in contributing to cleanlab, check out our contributing guide or just let us know in Slack!
