

Handling Label Errors in Text Classification Datasets
 Wei Jing Lok
Wei Jing Lok  Jonas Mueller
Jonas Mueller  Hui Wen Goh
Hui Wen Goh
Introduction
In machine learning and natural language processing, we train models to predict given labels, assuming that these labels are actually correct. However recent studies have found that even highly-curated ML benchmark datasets are full of label errors, and real-world datasets can be far lower quality. In light of these problems, the recent shift toward data-centric AI encourages data scientists to spend at least as much time improving their data as they do improving their models. No matter how much you tweak them, the quality of your models will ultimately depend on the quality of the data used to train and evaluate them.
The open-source cleanlab library provides a standard framework for implementing data-centric AI. cleanlab helps you quickly identify problems in messy real-world data, enabling more reliable machine learning and analytics. In this hands-on blog, we’ll use cleanlab to find label issues in the IMDb movie review text classification dataset. Commonly used to train/evaluate sentiment analysis models, this dataset contains 50,000 text reviews of films, each labeled with a binary sentiment polarity value indicating whether the review is overall positive (1) or negative (0).
Here’s a review that cleanlab found in the IMDB data, which has been incorrectly labeled as positive:
Like the gentle giants that make up the latter half of this film’s title, Michael Oblowitz’s latest production has grace, but it’s also slow and ponderous. The producer’s last outing, “Mosquitoman-3D” had the same problem. It’s hard to imagine a boring shark movie, but they somehow managed it. The only draw for Hammerhead: Shark Frenzy was it’s passable animatronix, which is always fun when dealing with wondrous worlds beneath the ocean’s surface. But even that was only passable. Poor focus in some scenes made the production seems amateurish. With Dolphins and Whales, the technology is all but wasted. Cloudy scenes and too many close-ups of the film’s giant subjects do nothing to take advantage of IMAX’s stunning 3D capabilities. There are far too few scenes of any depth or variety. Close-ups of these awesome creatures just look flat and there is often only one creature in the cameras field, so there is no contrast of depth. Michael Oblowitz is trying to follow in his father’s footsteps, but when you’ve got Shark-Week on cable, his introspective and dull treatment of his subjects is a constant disappointment.
The rest of this post demonstrates how to run cleanlab to find many more issues like this in the IMDB dataset. We also demonstrate how cleanlab can automatically improve your data to give you better ML performance without you having to change your model at all. You can easily use the same cleanlab workflow demonstrated here to find issues in your own dataset. You can run this workflow yourself in under 5 minutes:

Overview of steps to find label issues and improve models
Depicted below are the high-level steps involved in finding label issues in text classification data with cleanlab.
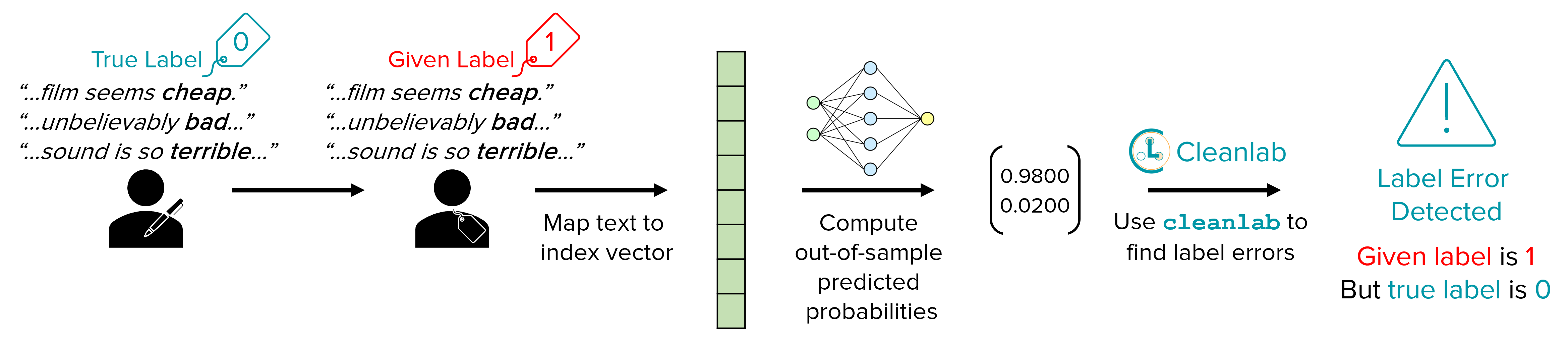
This blog will walk through the following workflow:
Construct a TensorFlow/Keras neural net and make it scikit-learn compatible using cleanlab’s
KerasWrapperSequential.Wrap the neural network with cleanlab’s
CleanLearningand use it to automatically compute out-of-sample predicted probabilities and identify potential label errors using thefind_label_issuesmethod.Train a more robust version of the same neural net after dropping the identified labeled errors using the same
CleanLearningobject.
The remainder of this blog lists the step-by-step code needed to implement this workflow.
Show me the code
We'll start by installing and importing some required packages (click to see code)
You can use pip to install the dependencies for this workflow:
pip install cleanlab sklearn pandas tensorflow tensorflow_datasetsOur first few Python commands will import some of the required packages and set some seeds for reproducibility.
import os
import random
import numpy as np
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3" # Controls amount of tensorflow output
SEED = 123456 # Just for reproducibility
np.random.seed(SEED)
random.seed(SEED)Prepare the dataset
The IMDb text dataset is readily provided in TensorFlow’s Datasets.
import tensorflow_datasets as tfds
raw_train_ds = tfds.load(name="imdb_reviews", split="train", batch_size=-1, as_supervised=True)
raw_test_ds = tfds.load(name="imdb_reviews", split="test", batch_size=-1, as_supervised=True)
raw_train_texts, train_labels = tfds.as_numpy(raw_train_ds)
raw_test_texts, test_labels = tfds.as_numpy(raw_test_ds)
num_classes = len(set(train_labels)) # 2 for this postive/negative binary classification task
print(f"Classes: {set(train_labels)}")Classes: {0, 1}Let’s print the first example in the train set.
i = 0
print(f"Example Label: {train_labels[i]}")
print(f"Example Text: {raw_train_texts[i]}")Example Label: 0
Example Text: "This was an absolutely terrible movie. Don't be lured in by Christopher Walken or Michael Ironside. Both are great actors, but this must simply be their worst role in history. Even their great acting could not redeem this movie's ridiculous storyline. This movie is an early nineties US propaganda piece. The most pathetic scenes were those when the Columbian rebels were making their cases for revolutions. Maria Conchita Alonso appeared phony, and her pseudo-love affair with Walken was nothing but a pathetic emotional plug in a movie that was devoid of any real meaning. I am disappointed that there are movies like this, ruining actor's like Christopher Walken's good name. I could barely sit through it."Reassuringly, at least this example seems properly labeled (recall 0 corresponds to a review labeled as negative).
The data is stored as two numpy arrays for each the train and test set:
raw_train_textsandraw_test_textsfor the movie reviews in text format,train_labelsandtest_labelsfor the labels.
To run this workflow on your own dataset, you can simply replace the text and labels above with your own dataset, and continue with the rest of the steps.
Your classes (and entries of train_labels / test_labels) should be represented as integer indices 0, 1, ..., num_classes - 1.
We'll next convert the text strings into index vectors which are better suited as inputs for neural network models: (click to see code)
Here we first define a function to preprocess the text data by:
- Converting it to lower case.
- Removing HTML break tags:
<br />. - Removing any punctuation marks.
import tensorflow as tf
import re
import string
def preprocess_text(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, "<br />", " ")
return tf.strings.regex_replace(stripped_html, f"[{re.escape(string.punctuation)}]", "")We use a TextVectorization layer to preprocess, tokenize, and vectorize our text data, thus making it suitable as input for a neural network.
from tensorflow.keras import layers
tf.keras.utils.set_random_seed(SEED)
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=preprocess_text,
max_tokens=max_features,
output_mode="int",
output_sequence_length=sequence_length,
)Adapting vectorize_layer to the text data creates a mapping of each token (i.e. word) to an integer index. Note that we only adapt the vectorization on the train set, as it is standard ML practice.
Subsequently, we can vectorize our text data in the train and test sets by using this mapping.
vectorize_layer.reset_state()
vectorize_layer.adapt(raw_train_texts)
train_texts = vectorize_layer(raw_train_texts).numpy()
test_texts = vectorize_layer(raw_test_texts).numpy()Our subsequent neural network models will directly operate on elements of train_texts and test_texts in order to classify reviews.
Define a classification model
Here, we build a simple neural network for text classification via the TensorFlow and Keras deep learning frameworks. We will also wrap it with cleanlab’s KerasWrapperSequential to make it compatible with sklearn (and hence CleanLearning).
Note: you can wrap any existing Keras model this way, by just replacing keras.Sequential with KerasWrapperSequential in your code. Once adapted in this manner, the neural net can be interacted with all your favorite scikit-learn model methods such as: fit() and predict().
Now you can train or use the network with just a single line of code!
from tensorflow.keras import layers, losses, metrics
from cleanlab.models.keras import KerasWrapperSequential
def get_nn_model():
model = KerasWrapperSequential(
[
tf.keras.Input(shape=(None,), dtype="int64"),
layers.Embedding(max_features + 1, 16),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(num_classes),
layers.Softmax()
],
compile_kwargs= {
"optimizer":"adam",
"loss":losses.SparseCategoricalCrossentropy(),
"metrics":metrics.CategoricalAccuracy(),
},
)
return modelThis network is similar to the fastText model, which is suprisingly effective for many text classification problems despite its simplicity.
The inputs to this network will be the elements of train_texts, and its outputs will correspond to the probability that the given movie review should be labeled as class 0 or 1 (i.e. whether it is overall negative or positive).
Use cleanlab to find potential label errors
Most real-world dataset contain some label errors, here we can easily define cleanlab’s CleanLearning object with the neural network model above and use its find_label_issues method to identify potential label errors.
CleanLearning provides a wrapper class that can easily be applied to any scikit-learn compatible model, which can be used to find potential label issues and train a more robust model if the original data contains noisy labels.
cv_n_folds = 5
num_epochs = 15
model = get_nn_model()
cl = CleanLearning(model, cv_n_folds=cv_n_folds)
label_issues = cl.find_label_issues(
X=train_texts,
labels=train_labels,
clf_kwargs={"epochs": num_epochs}
)The find_label_issues method above will perform cross validation to compute out-of-sample predicted probabilites for each example, which is used to identify label issues.
This method will return a label quality score for each example (scores between 0 and 1, where lower scores indicate examples more likely to be mislabeled), and also a boolean that specifies whether or not each example is identified to have a label issue (indicating it is likely mislabeled)
We can get the subset of examples flagged with label issues, and also sort by label quality score to find the indices of the 10 most likely mislabeled examples in our dataset.
identified_issues = label_issues[label_issues["is_label_issue"] == True]
lowest_quality_labels = label_issues["label_quality"].argsort()[:10].to_numpy()
print(
f"cleanlab found {len(identified_issues)} potential label errors in the dataset.\n"
f"Here are indices of the top 10 most likely errors: \n {lowest_quality_labels}"
)cleanlab found 1504 potential label errors in the dataset.
Here are indices of the top 10 most likely errors:
[22294 5204 15079 21889 10676 11186 15174 10589 18928 21492]Let’s review some of the most likely label errors:
To inspect these examples, we define a method to print any example from the dataset: print_as_df (click to see code)
import pandas as pd
pd.set_option("display.max_colwidth", None)
def print_as_df(index):
return pd.DataFrame({"texts": raw_full_texts[index], "labels": full_labels[index]}, [index])We can now inspect some of the top-ranked label issues identified by cleanlab. Below we highlight 3 reviews that are each labeled as positive (1), but should instead be labeled as negative (0).
print_as_df(22294)This movie is stuffed full of stock Horror movie goodies: chained lunatics, pre-meditated murder, a mad (vaguely lesbian) female scientist with an even madder father who wears a mask because of his horrible disfigurement, poisoning, spooky castles, werewolves (male and female), adultery, slain lovers, Tibetan mystics, the half-man/half-plant victim of some unnamed experiment, grave robbing, mind control, walled up bodies, a car crash on a lonely road, electrocution, knights in armour - the lot, all topped off with an incredibly awful score and some of the worst Foley work ever done. The script is incomprehensible (even by badly dubbed Spanish Horror movie standards) and some of the editing is just bizarre. In one scene where the lead female evil scientist goes to visit our heroine in her bedroom for one of the badly dubbed: "That is fantastical. I do not understand. Explain to me again how this is..." exposition scenes that litter this movie, there is a sudden hand held cutaway of the girl's thighs as she gets out of bed for no apparent reason at all other than to cover a cut in the bad scientist's "Mwahaha! All your werewolfs belong mine!" speech. Though why they went to the bother I don't know because there are plenty of other jarring jump cuts all over the place - even allowing for the atrocious pan and scan of the print I saw. The Director was, according to one interview with the star, drunk for most of the shoot and the film looks like it. It is an incoherent mess. It's made even more incoherent by the inclusion of werewolf rampage footage from a different film The Mark of the Wolf Man (made 4 years earlier, featuring the same actor but playing the part with more aggression and with a different shirt and make up - IS there a word in Spanish for "Continuity"?) and more padding of another actor in the wolfman get-up ambling about in long shot. The music is incredibly bad varying almost at random from full orchestral creepy house music, to bosannova, to the longest piano and gong duet ever recorded. (Thinking about it, it might not have been a duet. It might have been a solo. The piano part was so simple it could have been picked out with one hand while the player whacked away at the gong with the other.) This is one of the most bewilderedly trance-state inducing bad movies of the year so far for me. Enjoy. Favourite line: "Ilona! This madness and perversity will turn against you!" How true. Favourite shot: The lover, discovering his girlfriend slain, dropping the candle in a cartoon-like demonstration of surprise. Rank amateur directing there.Noteworthy snippets extracted from the first review:
“…incredibly awful score…”
“…worst Foley work ever done.”
“…script is incomprehensible…”
“…editing is just bizarre.”
“…atrocious pan and scan…”
“…incoherent mess…”
“…amateur directing there.”
print_as_df(5204)This low-budget erotic thriller that has some good points, but a lot more bad one. The plot revolves around a female lawyer trying to clear her lover who is accused of murdering his wife. Being a soft-core film, that entails her going undercover at a strip club and having sex with possible suspects. As plots go for this type of genre, not to bad. The script is okay, and the story makes enough sense for someone up at 2 AM watching this not to notice too many plot holes. But everything else in the film seems cheap. The lead actors aren't that bad, but pretty much all the supporting ones are unbelievably bad (one girl seems like she is drunk and/or high). The cinematography is badly lit, with everything looking grainy and ugly. The sound is so terrible that you can barely hear what people are saying. The worst thing in this movie is the reason you're watching it-the sex. The reason people watch these things is for hot sex scenes featuring really hot girls in Red Shoe Diary situations. The sex scenes aren't hot they're sleazy, shot in that porno style where everything is just a master shot of two people going at it. The woman also look like they are refuges from a porn shoot. I'm not trying to be rude or mean here, but they all have that breast implants and a burned out/weathered look. Even the title, "Deviant Obsession", sounds like a Hardcore flick. Not that I don't have anything against porn - in fact I love it. But I want my soft-core and my hard-core separate. What ever happened to actresses like Shannon Tweed, Jacqueline Lovell, Shannon Whirry and Kim Dawson? Women that could act and who would totally arouse you? And what happened to B erotic thrillers like Body Chemistry, Nighteyes and even Stripped to Kill. Sure, none of these where masterpieces, but at least they felt like movies. Plus, they were pushing the envelope, going beyond Hollywood's relatively prude stance on sex, sexual obsessions and perversions. Now they just make hard-core films without the hard-core sex.Noteworthy snippets extracted from the second review:
“…film seems cheap.”
“…unbelievably bad…”
“…cinematography is badly lit…”
“…everything looking grainy and ugly.”
“…sound is so terrible…”
print_as_df(15079)Like the gentle giants that make up the latter half of this film's title, Michael Oblowitz's latest production has grace, but it's also slow and ponderous. The producer's last outing, "Mosquitoman-3D" had the same problem. It's hard to imagine a boring shark movie, but they somehow managed it. The only draw for Hammerhead: Shark Frenzy was it's passable animatronix, which is always fun when dealing with wondrous worlds beneath the ocean's surface. But even that was only passable. Poor focus in some scenes made the production seems amateurish. With Dolphins and Whales, the technology is all but wasted. Cloudy scenes and too many close-ups of the film's giant subjects do nothing to take advantage of IMAX's stunning 3D capabilities. There are far too few scenes of any depth or variety. Close-ups of these awesome creatures just look flat and there is often only one creature in the cameras field, so there is no contrast of depth. Michael Oblowitz is trying to follow in his father's footsteps, but when you've got Shark-Week on cable, his introspective and dull treatment of his subjects is a constant disappointment.Noteworthy snippets extracted from the third review:
“…hard to imagine a boring shark movie…”
”Poor focus in some scenes made the production seems amateurish.”
“…do nothing to take advantage of…”
“…far too few scenes of any depth or variety.”
“…just look flat…no contrast of depth…”
“…introspective and dull…constant disappointment.”
With find_label_issues, cleanlab has shortlisted the most likely label errors to speed up your data cleaning process.
You should carefully inspect as many of these examples as you can for potential problems.
Train a more robust model from noisy labels
Manually inspecting and fixing the identified label issues may be time-consuming, but cleanlab can filter these noisy examples out of the dataset and train a model on the remaining clean data for you automatically.
First we’d like to establish a baseline by training and evaluating our original neural network model.
baseline_model = get_nn_model()
baseline_model.fit(X=train_texts, y=train_labels, epochs=num_epochs)
preds = baseline_model.predict(test_texts)
acc_og = accuracy_score(test_labels, preds)
print(f"\n Test accuracy of original neural net: {acc_og}")Test accuracy of original neural net: 0.86436Let’s now train and evaluate our original neural network model.
from sklearn.metrics import accuracy_score
model = KerasClassifier(get_net(), epochs=10)
model.fit(train_texts, train_labels)
preds = model.predict(test_texts)
acc_og = accuracy_score(test_labels, preds)
print(f"\n Test acuracy of original neural net: {acc_og}")Test acuracy of original neural net: 0.8738Now that we have a baseline, let’s check if using CleanLearning improves our test accuracy.
CleanLearning provides a wrapper that can be applied to any scikit-learn compatible model. The resulting model object can be used in the same manner, but it will now train more robustly if the data has noisy labels.
We can use the same CleanLearning object defined above, and pass the label issues we already computed into .fit() via the label_issues argument. This accelerates things; if we did not provide the label issues, then they would be recomputed via cross-validation. After that CleanLearning simply deletes the examples with label issues and retrains your model on the remaining data.
cl.fit(
X=train_texts,
labels=train_labels,
label_issues=cl.get_label_issues(),
clf_kwargs={"epochs": num_epochs})
pred_labels = cl.predict(test_texts)
acc_cl = accuracy_score(test_labels, pred_labels)
print(f"Test accuracy of cleanlab's neural net: {acc_cl}")Test accuracy of cleanlab's neural net: 0.87296We can see that the test set accuracy slightly improved as a result of the data cleaning. Note that this will not always be the case, especially if we are evaluating on test data that are themselves noisy. The best practice is to run cleanlab to identify potential label issues and then manually review them, before blindly trusting any accuracy metrics. In particular, the most effort should be made to ensure high-quality test data, which is supposed to reflect the expected performance of our model during deployment.
Conclusion
With one line of code, cleanlab automatically shortlists the most likely label errors to speed up your data cleaning process. Subsequently, you can carefully inspect the examples in this shortlist for potential problems. You can see that even widely-studied datasets like IMDB-reviews contain problematic labels. Never blindly trust your data! You should always check it for potential issues, many of which can be automatically flagged with cleanlab.
A simple way to deal with such issues is to remove examples flagged as potentially problematic from our training data.
This can be done automatically via cleanlab’s CleanLearning class.
In some cases, this simple procedure can lead to improved ML performance without you having to change your model at all!
In other cases, you’ll need to manually handle the issues cleanlab has identified.
For example, it may be better to manually fix some examples rather than omitting them entirely from the data.
Be particularly wary about label errors lurking in your test data, as test sets guide many important decisions made in a typical ML application.
While this post studied movie-review sentiment classification with Tensorflow neural networks, cleanlab can be easily used for any dataset (image, text, tabular, etc.) and with any classification model.
While cleanlab helps you automatically find data issues, an interface is needed to efficiently fix these issues your dataset. Cleanlab Studio finds and fixes errors automatically in a (very cool) no-code platform. Export your corrected dataset in a single click to train better ML models on better data. Try Cleanlab Studio at https://app.cleanlab.ai/.
cleanlab is undergoing active development, and we’re always interested in more open-source contributors!
If you want to stay up-to-date on the latest developments from the Cleanlab team, please:
- Watch and star our GitHub: https://github.com/cleanlab/cleanlab
- Follow us on LinkedIn: https://www.linkedin.com/company/cleanlab/
- Follow us on Twitter: https://twitter.com/CleanlabAI
- Like & Follow us on Facebook: https://www.facebook.com/CleanlabAI/
- Join our Cleanlab Community Slack
Additional References
- Example code: Using Cleanlab, HuggingFace, and Keras to find label issues in IMDB text dataset
- Example code: Using Cleanlab and FastText to find label issues in Amazon Reviews text dataset
- Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
- An Introduction to Confident Learning: Finding and Learning with Label Errors in Datasets
- cleanlab documentation
- Cleanlab Studio: no-code data improvement