

Detecting Label Errors in Entity Recognition Data
 Wei-Chen (Eric) Wang
Wei-Chen (Eric) Wang  Elías Snorrason
Elías Snorrason  Jonas Mueller
Jonas Mueller
While our past work alerted the ML community that classification datasets often have incorrect labels, mislabeled data is even more prevalent in ML tasks where annotators provide numerous fine-grained labels for each input example. For example in entity recognition, each word in a sentence receives its own label on what type of entity it describes. Based on user requests, we’ve extended cleanlab’s label quality algorithms to entity recognition tasks and you can now find label errors in such token classification data via one line of open-source code!
We ran this code on one of the most famous text datasets: CoNLL-2003. Despite serving as a gold-standard for benchmarking entity recognition models, CoNLL-2003 contains hundreds of label errors! Here are a few of the top-ranked ones identified by cleanlab:
Soccer - Keane Signs Four-year Contract With Manchester United.
Word: United | Given CoNLL label: LOCATION | Label should be: ORGANIZATION
But one must not forget that the Osce only has limited powers there,” said Cotti, who is also the Swiss foreign minister.”
Word: Cotti | Given CoNLL label: OTHER | Label should be: PERSON
A Reuter consensus survey sees medical equipment group Radiometer reporting largely unchanged earnings when it publishes first half 19996/97 results next Wednesday.
Word: Wednesday | Given CoNLL label: ORGANIZATION | Label should be: MISC
Little change from today’s weather expected.
Word: Little | Given CoNLL label: PERSON | Label should be: OTHER (not an entity)
Let’s march together,” Scalfaro, a northerner himself, said.
Word: Let | Given CoNLL label: LOCATION | Label should be: OTHER (not an entity)
Born in 1937 in the central province of Anhui, Dai came to Shanghai as a student and remained in the city as a prolific author and teacher of Chinese.
Word: Born | Given CoNLL label: LOCATION | Label should be: OTHER (not an entity)
Using cleanlab in entity recognition
Here is the code we ran to find the above dataset annotation errors and hundreds more:
from cleanlab.token_classification.filter import find_label_issues
issues = find_label_issues(per_token_labels, per_token_pred_probs)The inputs for each sentence (corresponding to an example in the dataset) are the given label (one of K classes) for each word in the sentence and predicted class probabilities for this word output by any trained token classification model. An example for a dataset with K=2 classes:
per_token_labels = [..., [1, 0, 0], ...]
per_token_pred_probs = [..., np.array([[0.8,0.2], [0.9,0.1], [0.3,0.7]]), ...]cleanlab.token_classification can be used with any entity recognition model trained via any strategy. You can easily use your most accurate model with cleanlab to most effectively identify issues in a dataset and then fix these issues to train an even better version of the same model!
For instance, we found the above CoNLL issues using a basic bert-base-NER model from HuggingFace. More broadly, you can use this same method to detect errors in arbitrary sequence prediction (sequence tagging) datasets.
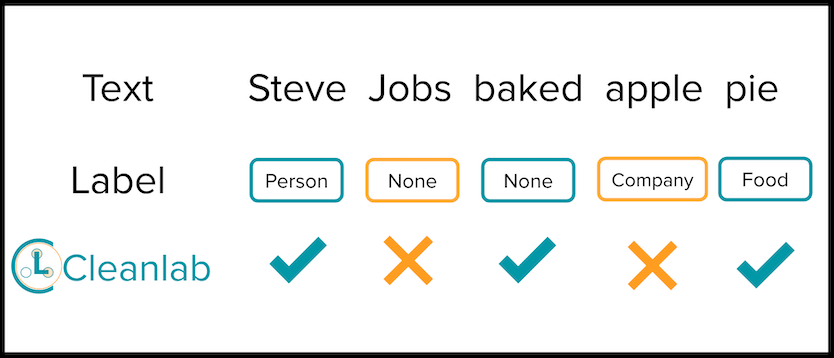
How mislabeled text is detected
We conducted extensive research on algorithms for mislabeled entity recognition data, described in our paper: Detecting Label Errors in Token Classification Data
Our research considers many different algorithms to estimate token label quality and evaluates them on real-world entity recognition data with actual label errors (as opposed to synthetic errors common in academic studies). Cleanlab employs the algorithm that performed best.
A key consideration is to develop a score for each sentence rather than only for individual words. To review whether a particular word was mislabeled or not in the CoNLL examples above, you probably had to read the full sentence to understand the broader context in which this word appears. For example, labeling the word apple as an ORGANIZATION entity would be correct in the sentence: ”I bought a computer from apple” but incorrect in the sentence: ”I ate an apple”. Given we must read sentences to verify individual labels, we can most efficiently find label errors via help from an algorithm that prioritizes sentences containing mislabeled words for our review.
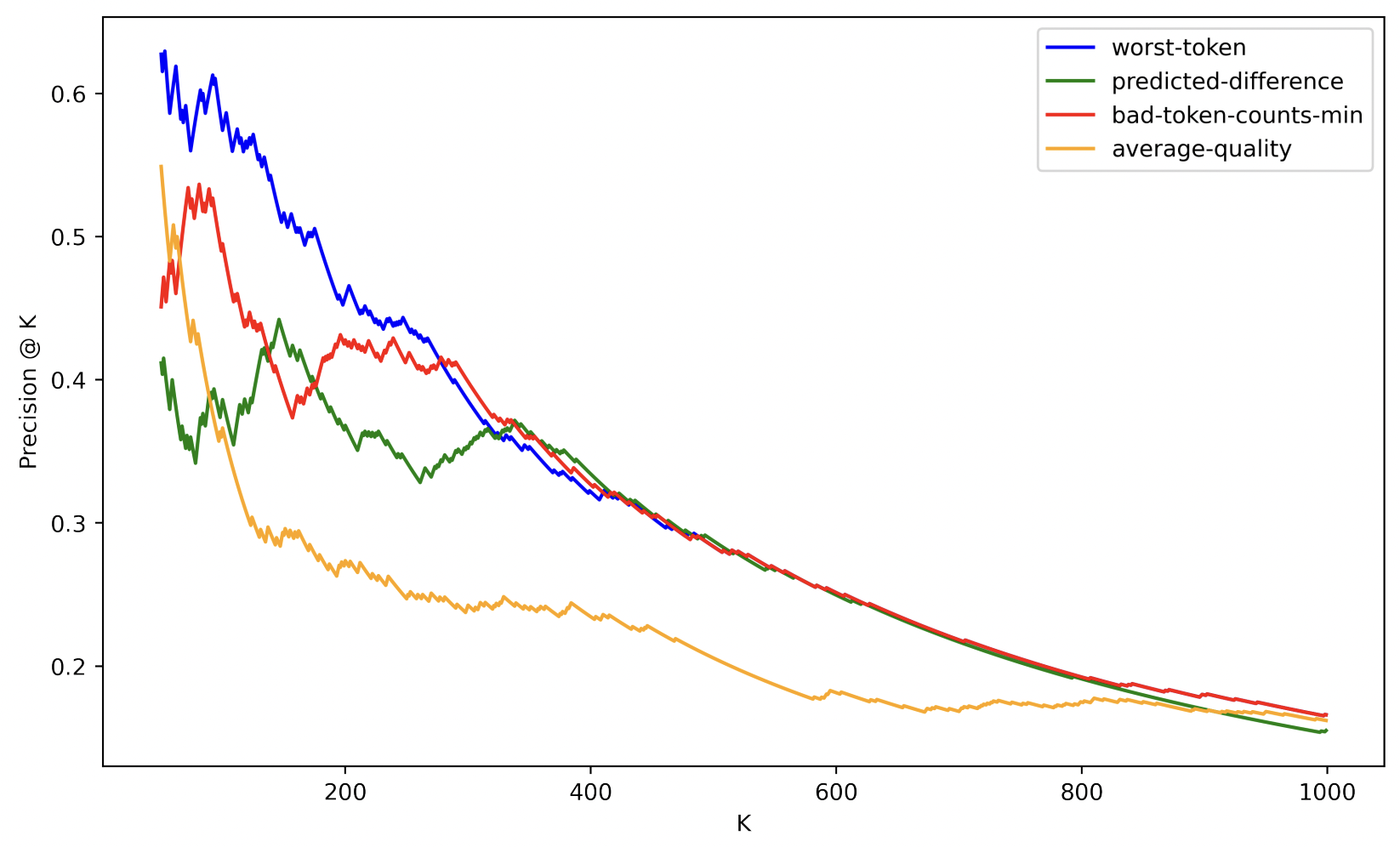
Our research reveals that scoring sentences via the minimum of label quality estimates for each of their tokens provides better precision/recall than other methods for identifying those sentences containing label errors. This correponds to evaluating a sentence based on its worst token, and the precision achieved by this strategy on real data is plotted below against that of other methods for detecting sentences with label errors. We have released the code to reproduce all our benchmarks on GitHub.
More findings about the CoNLL-2003 dataset
Beyond finding which words are mislabeled in which sentences, cleanlab.token_classification.summary also provides other useful functions for better understanding an entity recognition dataset. For instance, to determine what words are most commonly mislabeled overall throughout the dataset, which can indicate systematic misunderstandings by the data annotators. For the CoNLL-2003 data, cleanlab infers that / is the most commonly mislabeled word overall (some punctuation characters like / are tokenized as their own words), followed by: Chicago, U.S., Digest, Press, New, and and.
Amongst the 5 possible classes {PERSON, ORGANIZATION, LOCATION, MISCELLANEOUS, OTHER}, the most common type of label error in CoNLL-2003 appears to be assigning the non-entity label OTHER to words that are actually part of an entity. This is an understandable oversight by the human annotators who had to rapidly go through large volumes of text. Another common error appears to be confusing the ORGANIZATION and LOCATION classes, e.g. some annotators may fail to label United correctly in both Manchester United and United States.
Get started with cleanlab to improve text data
- 5min tutorial on how to apply cleanlab to data from token classification tasks like entity recognition
- Example notebook demonstrating how to train a modern entity recognition model and use it with cleanlab
- 5min tutorial on how to apply cleanlab to text data from standard classification tasks
- The source code of all our algorithms is fully open-source for you to understand their inner workings (and to contribute if you spot opportunities!)
- Cleanlab Studio: no-code data improvement (for text and other data modalities)
Beyond token classification
While cleanlab was originally focused on classification data, the library is growing beyond this scope to provide useful tools for improving the quality of far more types of data. Our team is hard at work developing new algorithms to properly extend cleanlab’s label error detection capabilities to ML/NLP tasks beyond sequence prediction with text data. Like entity recognition, other common tasks also involve labeling different fine-grained parts of an example, such as semantic segmentation of image data.
We invite you to submit requests for what type of ML problems you want to assess data quality in and join our Slack discussions on what functionality will enable more data-centric AI!