

CleanVision: Audit your Image Data for better Computer Vision
 Sanjana Garg
Sanjana Garg  Ulyana Tkachenko
Ulyana Tkachenko  Yiming Chen
Yiming Chen  Elías Snorrason
Elías Snorrason  Jonas Mueller
Jonas Mueller
Introducing CleanVision: an open-source Python library that scans any image dataset for common real-world issues such as images which are blurry, under/over-exposed, oddly sized, or (near) duplicates of others. Here are some of the issues CleanVision automatically detected (with just 3 lines of code) in the famous Caltech-256 dataset.


Teaching computers to see via massive datasets and models has produced astounding progress for image generation, classification, segmentation, and related tasks like object detection. As computer vision techniques graduate from the lab to real-world applications, data quality poses a major challenge. ML models can only be as good as the data they are trained on.
To help you improve your data, we’ve just open-sourced CleanVision, a package to quickly audit any image dataset for a broad range of common issues lurking in real-world data. Instead of relying on manual inspection, which can be time-consuming and lack coverage, CleanVision provides an automated systematic approach for detecting data issues. With just a few lines of code (that can be used to audit any image data), we ran CleanVision on some popular computer vision datasets and identified many issues in each.
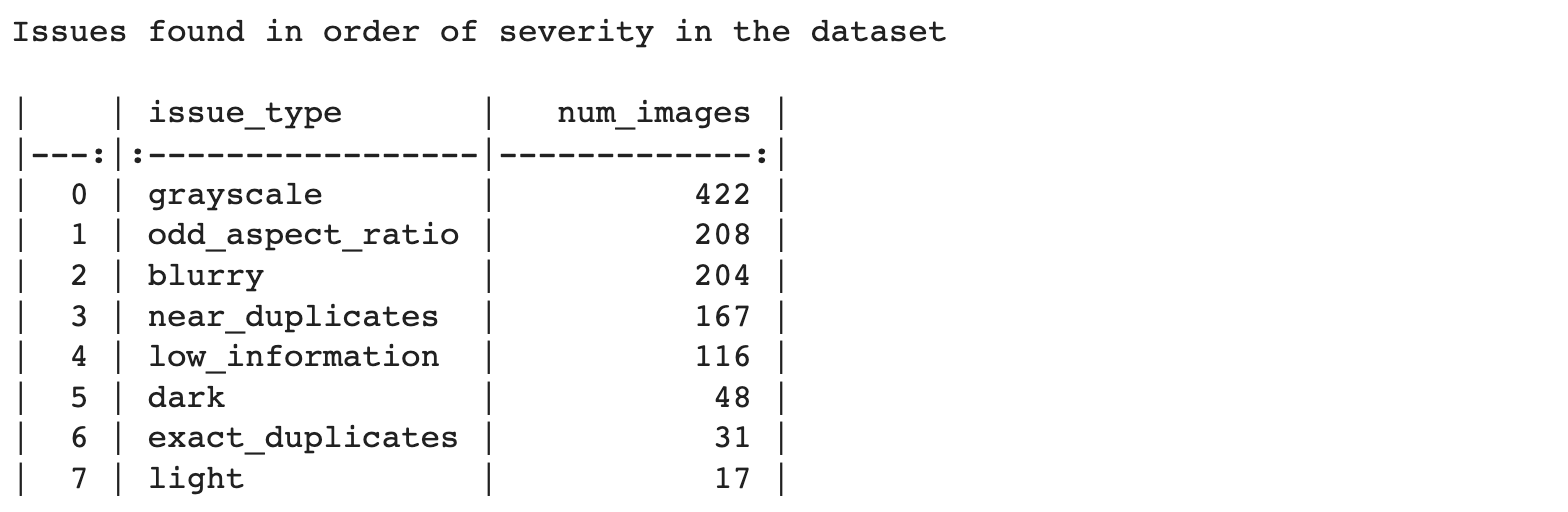
Issues in the Caltech-256 dataset
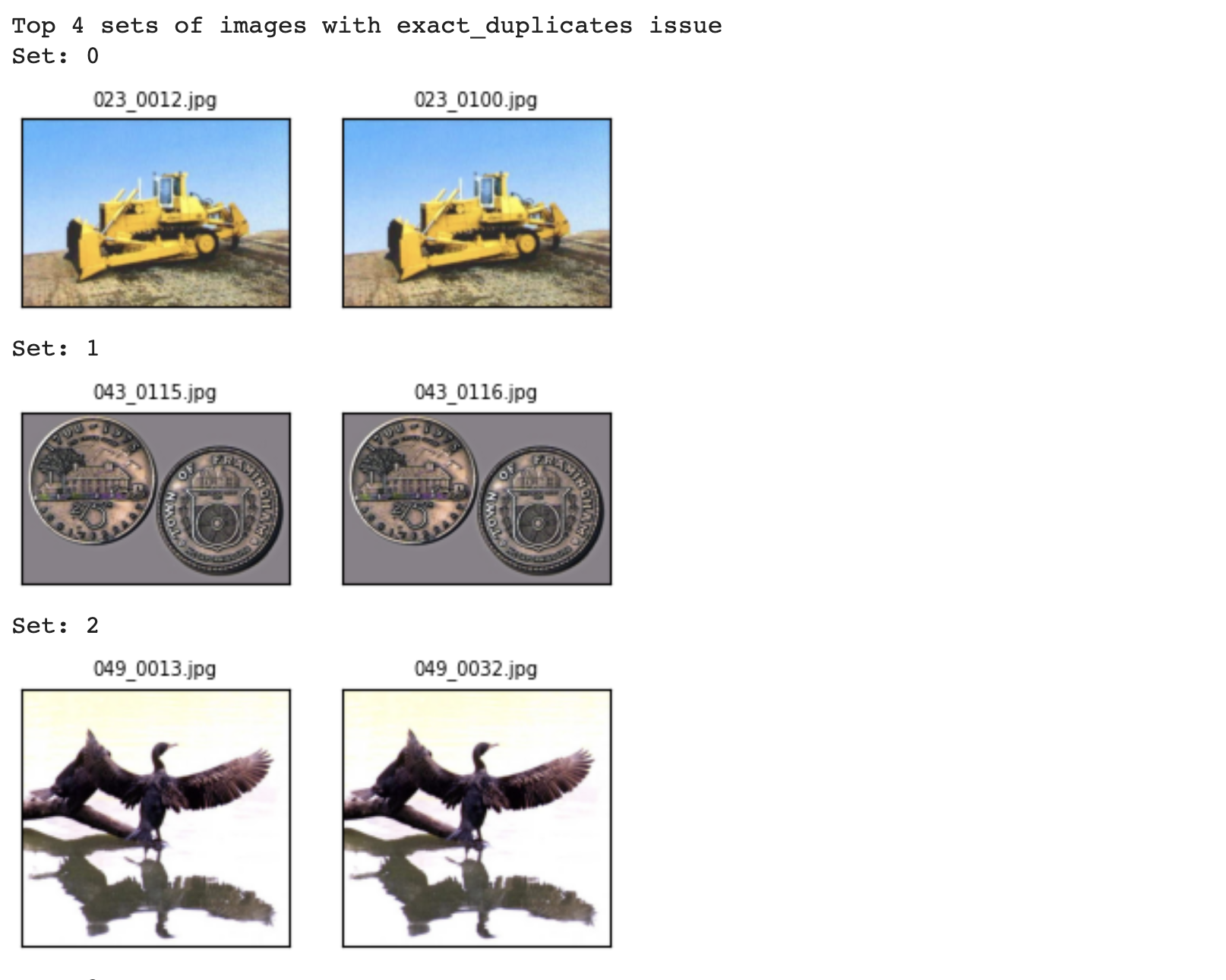
Widely used for benchmarking object recognition methods, the Caltech-256 dataset consists of 30,607 real-world images (of different sizes) stemming from 257 classes. CleanVision identified several issues in this dataset including images that are: grayscale, low information, blurry, near duplicates, or have an odd aspect ratio. All of the images in the car-side class are grayscale images, which can cause models to spuriously associate the car-side class with the grayscale attribute rather than focusing on the object’s features. Moreover, CleanVision detected low-information images that do not resemble real-world images like stick figures and graphs. Closer inspection reveals some of these images are mislabeled in the dataset. For example, the sigmoid like plot in the low information set of images is wrongly labeled as a housefly. Detecting low-information images is also important when training generative models, as these can be easily memorized by the model and lead to model regurgitation instead of synthesizing new images.
More generally, it is good to know these issues exist in your data before you dive into modeling it. Especially if they are easily detected with CleanVision!
Getting the above results for the Caltech-256 dataset was as easy as just running this code:
from cleanvision.imagelab import Imagelab
imagelab = Imagelab(data_path="path_to_dataset")
imagelab.find_issues()
imagelab.report()The image files can simply live in a path_to_dataset/ folder and CleanVision will work with most image formats.
For the Caltech-256 images, CleanVision outputs the following report (click to view it)








You can use this notebook to easily try it yourself!
Why is image data quality important?
Consider the following quotes from the OpenAI blog on DALLE-2, one of the best generative image models available today produced by an organization that has created many of the world’s best ML models. While these quotes are specific to generative modeling, a wealth of literature on data-centric AI has found these points highly relevant in other computer vision tasks.
Since training data shapes the capabilities of any learned model, data filtering is a powerful tool for limiting undesirable model capabilities.
We prioritized filtering out all of the bad data over leaving in all of the good data. This is because we can always fine-tune our model with more data later to teach it new things, but it’s much harder to make the model forget something that it has already learned.
We designed CleanVision to help you filter out the bad data in your applications, like OpenAI did before training DALLE-2.
When we studied our dataset of regurgitated images, we noticed two patterns. First, the images were almost all simple vector graphics, which were likely easy to memorize due to their low information content. Second, and more importantly, the images all had many near-duplicates in the training dataset. […] Once we realized this, we used a distributed nearest neighbor search to verify that, indeed, all of the regurgitated images had perceptually similar duplicates in the dataset. Other works have observed a similar phenomenon in large language models, finding that data duplication is strongly linked to memorization.
To test the effect of deduplication on our models, we trained two models with identical hyperparameters: one on the full dataset, and one on the deduplicated version of the dataset. […] we found that human evaluators slightly preferred the model trained on deduplicated data, suggesting that the large amount of redundant images in the dataset was actually hurting performance.
These are merely a few of the reasons behind the need to check for issues like (near) duplicates and low information images. Each type of issue that CleanVision detects is something that might hinder training the best possible model on your data.
Why should CleanVision be a first step in computer vision workflows?
Beyond being easy to use and fast to run, CleanVision offers more comprehensive coverage of possible issues in an image dataset. Such automated methods are much more systematic than manually checking the data – CleanVision results are reproducible and can be used to compare datasets directly.
Unlike most computer vision packages today which require GPUs, CleanVision can efficiently audit most image datasets on a CPU. Since it focuses on the image files themselves, CleanVision can be useful in all computer vision tasks, including supervised learning and generative modeling. For supervised learning datasets, CleanVision does not audit the quality of the dataset labels – instead use the cleanlab library to easily do that.
Issues in other famous image datasets
We used the exact same few lines of code shown above to run CleanVision on other famous image datasets cited in hundreds of papers each year: Food101, CUB-200-2011, and CIFAR-10. These datasets are large enough that manual identification of issues is impractical. Although these datasets are quite diverse, we only needed to run the exact same 3 lines of code shown above to audit each one.
For datasets with train and test splits, we merged these into a single dataset prior to running CleanVision. Below, we summarize some issues detected in these datasets. Notebooks to reproduce these results and see all of the detected issues are available in the cleanvision-examples repository.
Food101 Dataset

Food-101 consists of 101 food categories with 1000 images per category. CleanVision detected several issues in this dataset like images that are dark, blurry, exact duplicates, near duplicates and grayscale. In fact, it found a few grayscale images which are not food images at all! Additionally, there are around 100 pairs of near and exact duplicates in the dataset with a slight change in lighting or some text in the image. As previously discussed, uniqueness is an important aspect of data quality and having (near) duplicate images in the dataset can negatively impact model performance. The last row depicted above consists of dark images detected by CleanVision, which are labeled as: breakfast_burrito, bibimbap, macarons, bread_pudding, bread_pudding, oysters in order from left to right. However, the correctness of these labels is hard to verify, and thus dark/blurry images can contribute to noise in the dataset.
CUB-200-2011 Dataset

Caltech-UCSD Birds-200-2011 (CUB-200-2011) contains 11,788 images depicting birds from 200 subcategories. CleanVision detected fewer issues in this dataset compared to Caltech-256 and Food-101, but there are still some noteworthy issues depicted above. Indicative of a labeling error, the pair of nearly-duplicated brown birds actually belong to 2 different classes – one is labeled as Whip Poor Will and the other Chuck Will Widow. Odd aspect ratio and blurry images can also be problematic, especially for the task of fine-grained classification if important features of the bird are obfuscated. The low information images in this dataset don’t look like real images but more like drawings and provide very little information on the fine-grained features of the birds. The blue bird image flagged as low information has label ivory gull, which seems to be incorrect given that bird should be white.
The existence of exact duplicates in CUB-200-2011, Food-101, and Caltech-256 indicates that even basic curation steps were overlooked when establishing these ML benchmarks. The situation is more dire in many datasets from real-world applications, which are far less curated than these benchmark datasets (e.g. due to tight deadlines). The following table lists the number of near/exact duplicate images in each dataset we audited with CleanVision.
| Dataset | # Near Duplicates | # Exact Duplicates |
|---|---|---|
| Caltech-256 | 167 | 31 |
| Food-101 | 92 | 118 |
| CUB-200-2011 | 10 | 2 |
| CIFAR-10 | 40 | 0 |
CIFAR-10 Dataset

CIFAR-10 has 60,000 32x32 color images. This dataset had the least number of issues amongst the ones we evaluated here. The most prevalent issues found in this dataset are near duplicated, dark, light, and low information images. The near duplicated car image is a form of leakage between train and test set (the grayscale car image is in the train split whereas the same car image in color is part of the test split). Such biased evaluation can give a false sense of the model’s accuracy and how well it will actually perform in deployment. CleanVision finds that CIFAR-10 contains 20 sets of near duplicate images. There are also some very light/dark and low information images in the dataset, from which it is very difficult to gather any useful features. It is hard to tell that the light images are airplanes and the low information image is a bird. A model trained on such ill-posed data may learn spurious correlations if we are not careful.
Resources to learn more
- Github Repo - Check out the CleanVision code and contribute your own ideas.
- Quickstart Tutorial - See additional things you can do with CleanVision in 5min.
- Example Notebooks - Includes code to run CleanVision on the above datasets to reproduce all of the issues displayed in this article.
- Documentation - Understand the various APIs this package offers.
- Slack Community - Join our community of scientists/engineers to ask questions, see how others are using CleanVision, and brainstorm new ideas.
- Cleanlab Studio - A no-code solution to automatically fix data and label issues in image datasets.
This is only the start. We have a much larger “vision” for the CleanVision package, and would love your help inventing the future of open-source Data-Centric AI!