

Automated Data Quality at Scale
 Anish Athalye
Anish Athalye  Angela Liu
Angela Liu
Large-scale datasets used in enterprise data analytics and machine learning are often full of errors, leading to lower reliability, lost productivity, and increased costs. The modern solution to this problem is data-centric AI, but applying these techniques at scale used to be challenging even for a team of experts. A couple years ago, it was the sort of work that took MIT grad students months to do. Now, you can automatically find and fix issues in data at scale, effortlessly curating high-quality datasets!
As a case study, this post demonstrates how Cleanlab Studio, a tool built on top of data-centric AI algorithms, can analyze the full ImageNet training set (1.2 million images) to find and fix the sorts of issues commonly found in enterprise image datasets, such as mislabeled images, outliers, and near-duplicates. Furthermore, it shows how the tool can be used to derive higher-level insights about the dataset as a whole, such as improvements to the ontology. All analysis, charts, and tables in this post were produced fully automatically by Cleanlab Studio.
An accompanying tutorial walks through how you can apply Cleanlab Studio to improve your own dataset.
Issues in ImageNet
After uploading a dataset or pointing Cleanlab Studio to an existing dataset in cloud storage, Studio automatically analyzes the data using state-of-the-art autoML and data-centric algorithms that we have developed to find issues such as label issues, outliers, and near-duplicates.
Label issues
ImageNet is a single-label classification dataset, where each image is assigned exactly one of 1,000 labels. Cleanlab Studio finds tens of thousands of label issues in ImageNet, where the given label might not be correct. For each data point, it computes a label quality score, so you can prioritize the most severe issues. The data in ImageNet is annotated by humans, so unsurprisingly, there are many mislabeled examples, such as an image labeled “beaver” (a type of animal) when it is really a “traffic sign”:

You could imagine why such an image might confuse a human annotator! Looking through the results reveals several more complex label issues where images aren’t simply mislabeled, such as this multi-label example, which contains both a “traffic light” and a “traffic sign”:
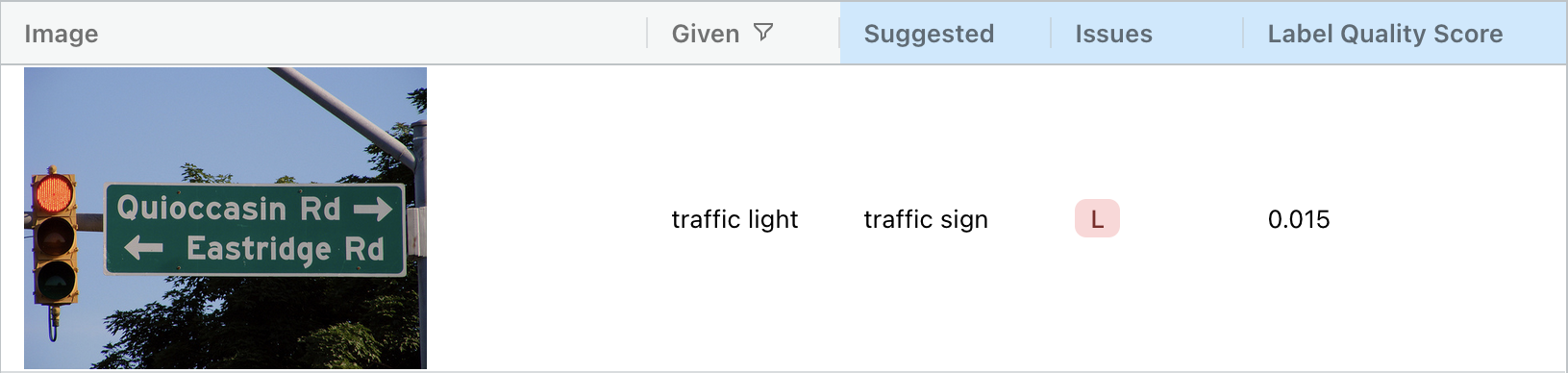
ImageNet-1K is a single-label dataset; the existence of examples like this suggest that either the data should be modified to omit the multi-label examples (why should an ML model be penalized for predicting that the image above is a “traffic sign”?), or the task should be re-framed as a multi-label classification problem (which Cleanlab Studio also supports).
A more subtle form of multi-label issue is a has-a relationship. ImageNet contains the class “shoe store”, but it also has classes like “running shoe” and “clogs”. Usually, shoe stores contain shoes! So many of the images labeled “shoe store” contain running shoes, for example, and could also appropriately be labeled “running shoe”. We can find such issues by filtering for images with given label “shoe store”:
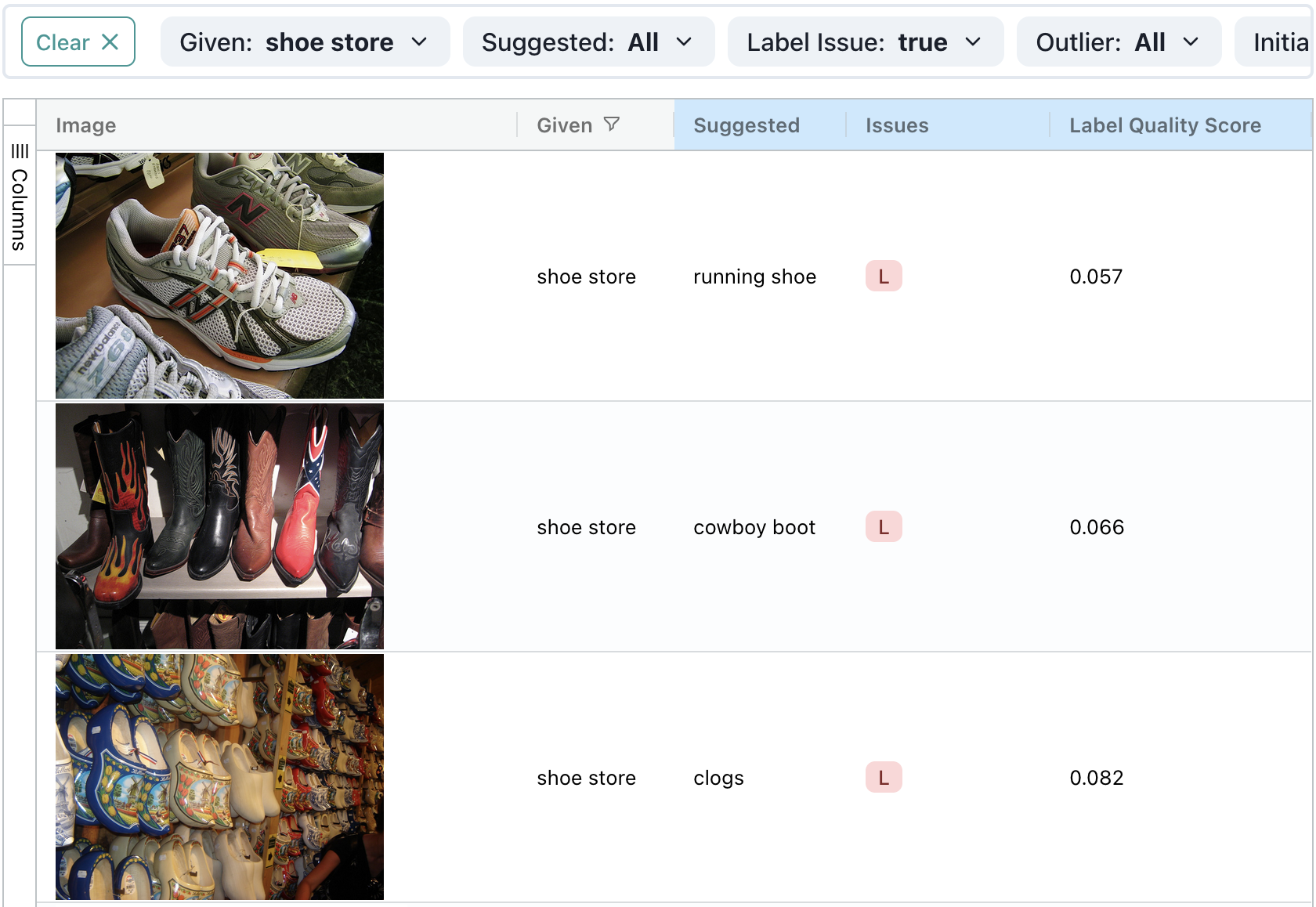
One way this ontological issue could be resolved in a single-label dataset is by combining all of the shoe-related classes — “shoe store”, and all the classes representing items found within a shoe store like “running shoes” and “clogs” — into a single new “shoes” class.
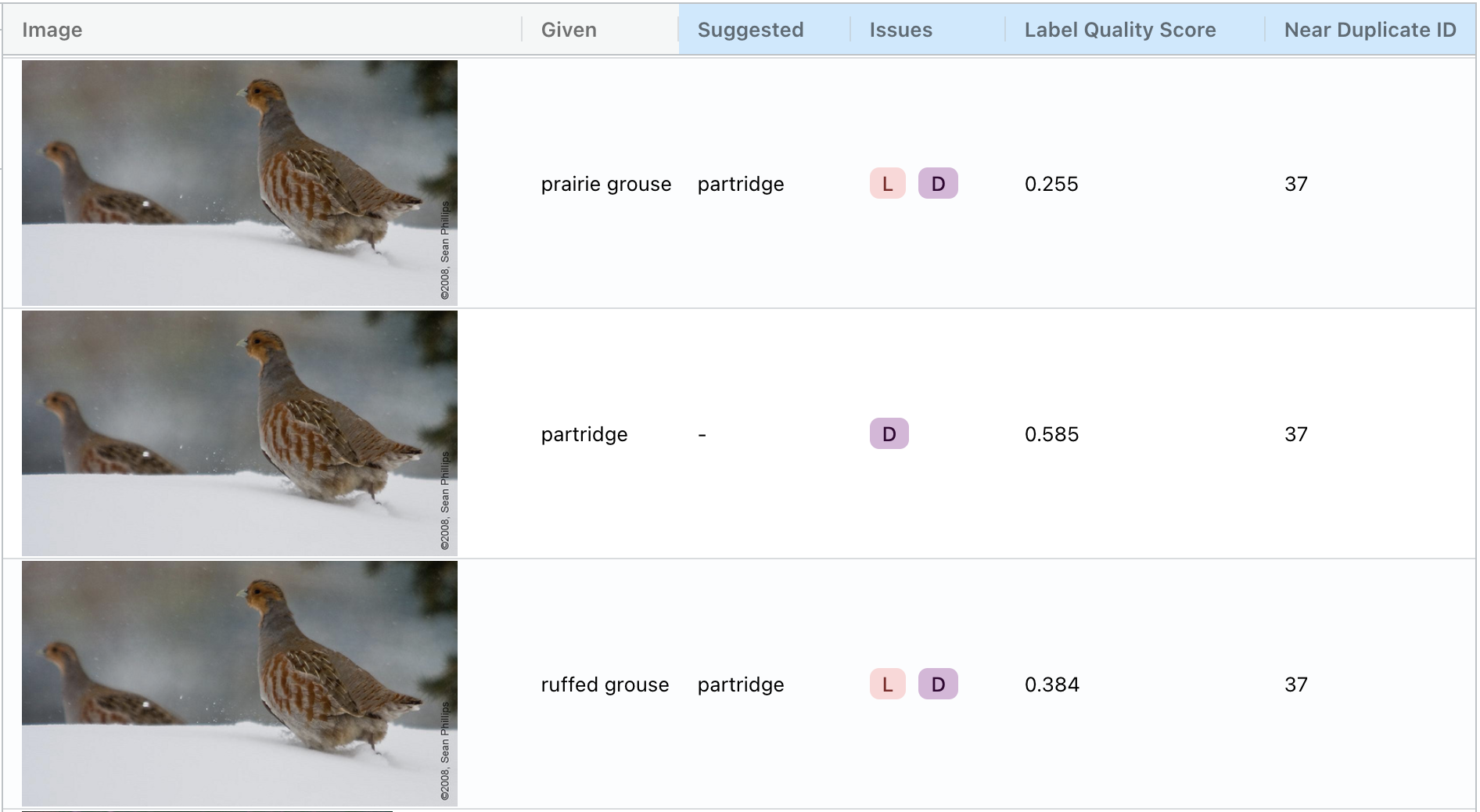
A related type of issue is an is-a relationship. A “flagpole” and a “maypole” are both, by definition, a type of “pole”. The data points below are all labeled “pole”, but all of these examples would be more appropriately labeled with the more specific class:
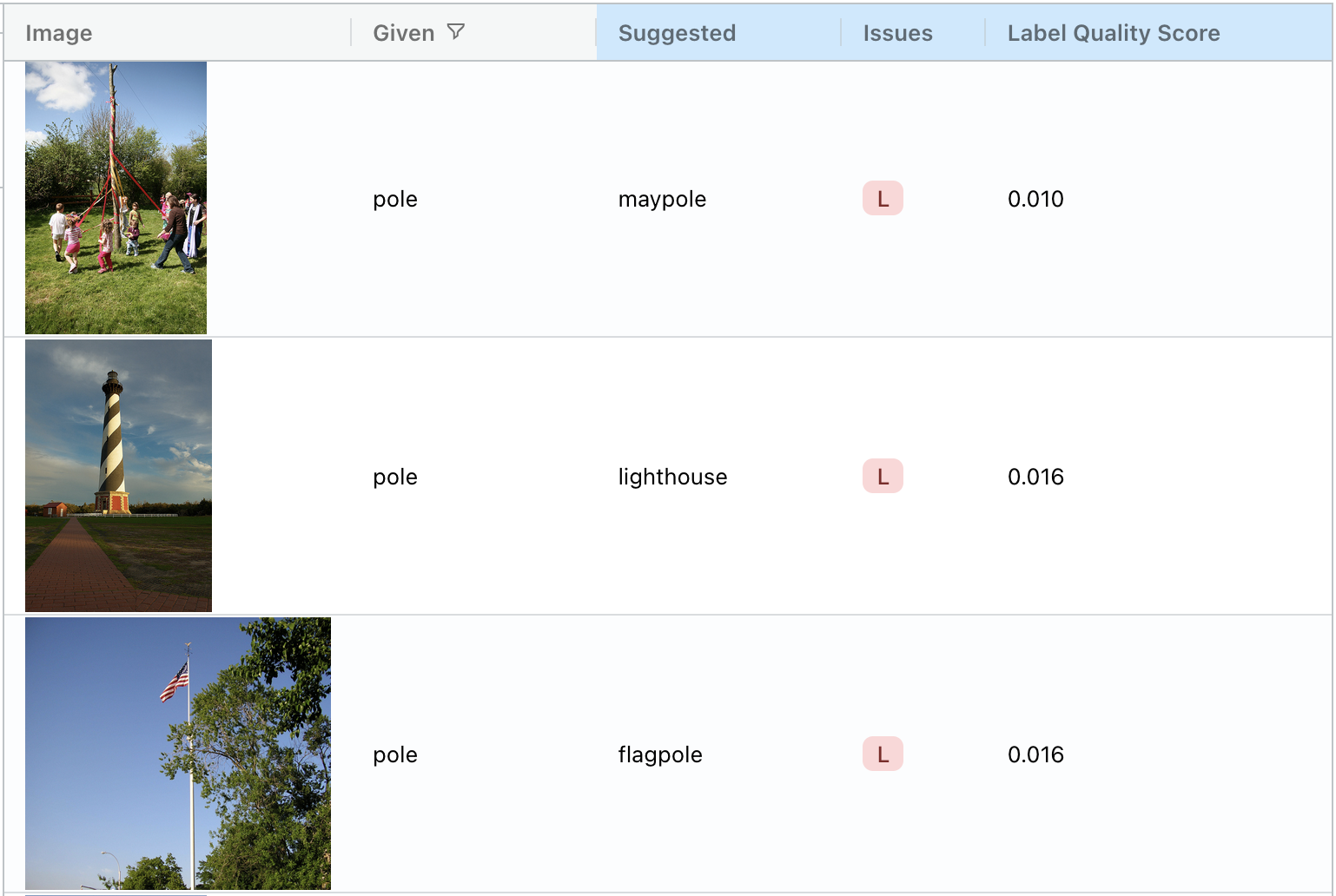
In a single-label classification dataset, is-a relationships can be resolved by removing the more general class and giving each example the correct (and more specific) label, such as the label that Cleanlab Studio automatically suggests.
To get a higher-level understanding of the types of issues in ImageNet, we can look at charts like the following, which summarizes the most commonly-suggested corrections to the data. For example, there are 510 examples of “projectile” in ImageNet that potentially should be corrected to “missile”:
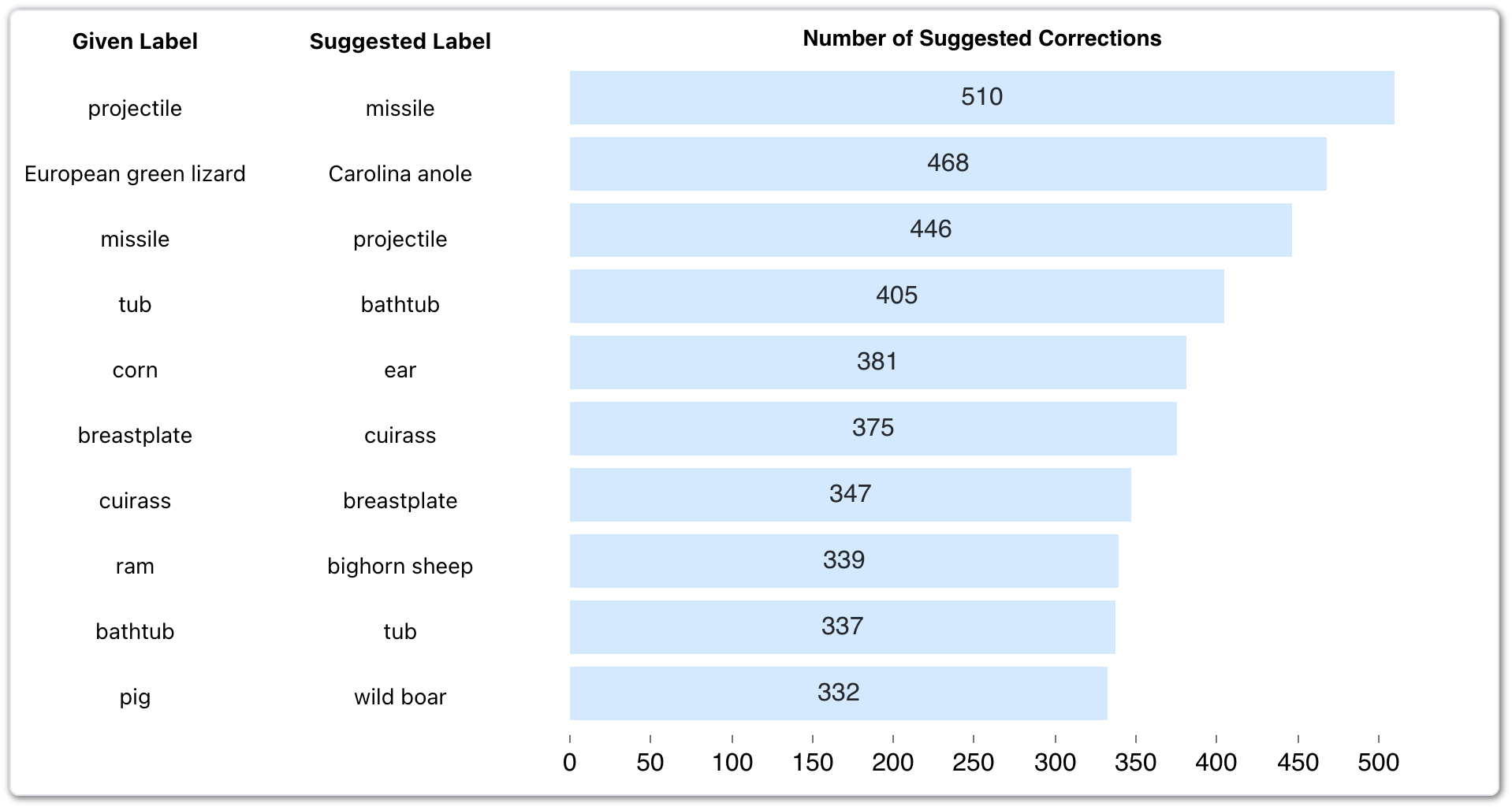
We can derive higher-level insights about the dataset and ontology from this chart. We see that “missile” and “projectile” are commonly confused (first and third row): a missile is a type of projectile, so this is an ontological issue in the dataset. A “European green lizard” and “Carolina anole” look very similar, so it makes sense that they’re easily confused. “Ear” in this dataset refers to ears of corn, so the two classes “corn” and “ear” are actually referring to the same object.
Outliers
Outliers are data points that differ significantly from other data points. Cleanlab Studio finds thousands of outliers in ImageNet, such as these:
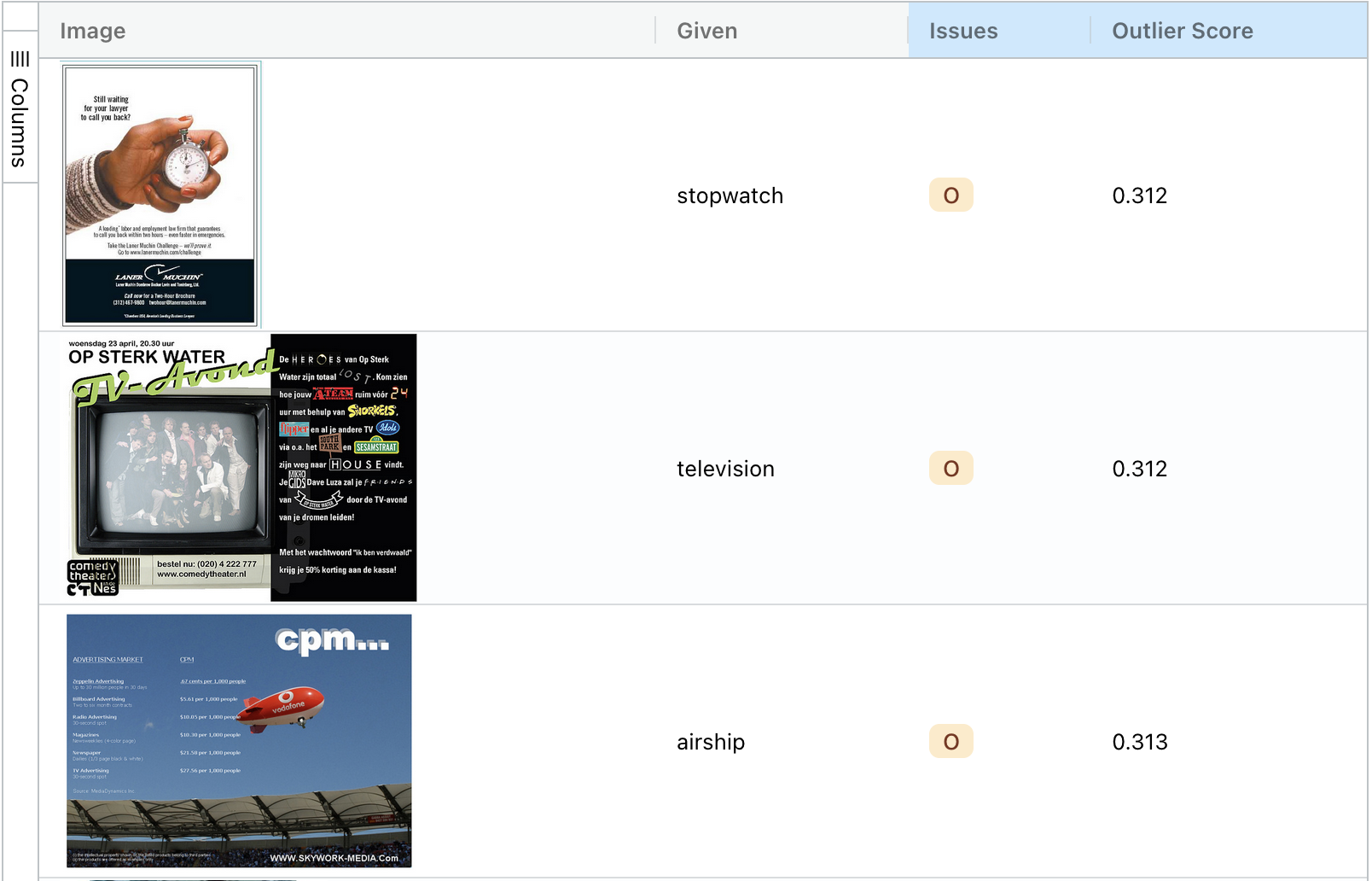
The first image appears to be a magazine ad that contains a picture of a stopwatch, but it is not itself a stopwatch. The other images have similar issues. In many cases, outliers should simply be removed from the dataset.
Near duplicates
Duplicate or near-duplicate images in a dataset can result in a variety of issues including data leakage, where the same data point appears in both the training and test set. In ImageNet, we find hundreds of duplicated images, many of which exhibit a particular kind of issue, where the same image appears multiple times with different labels:
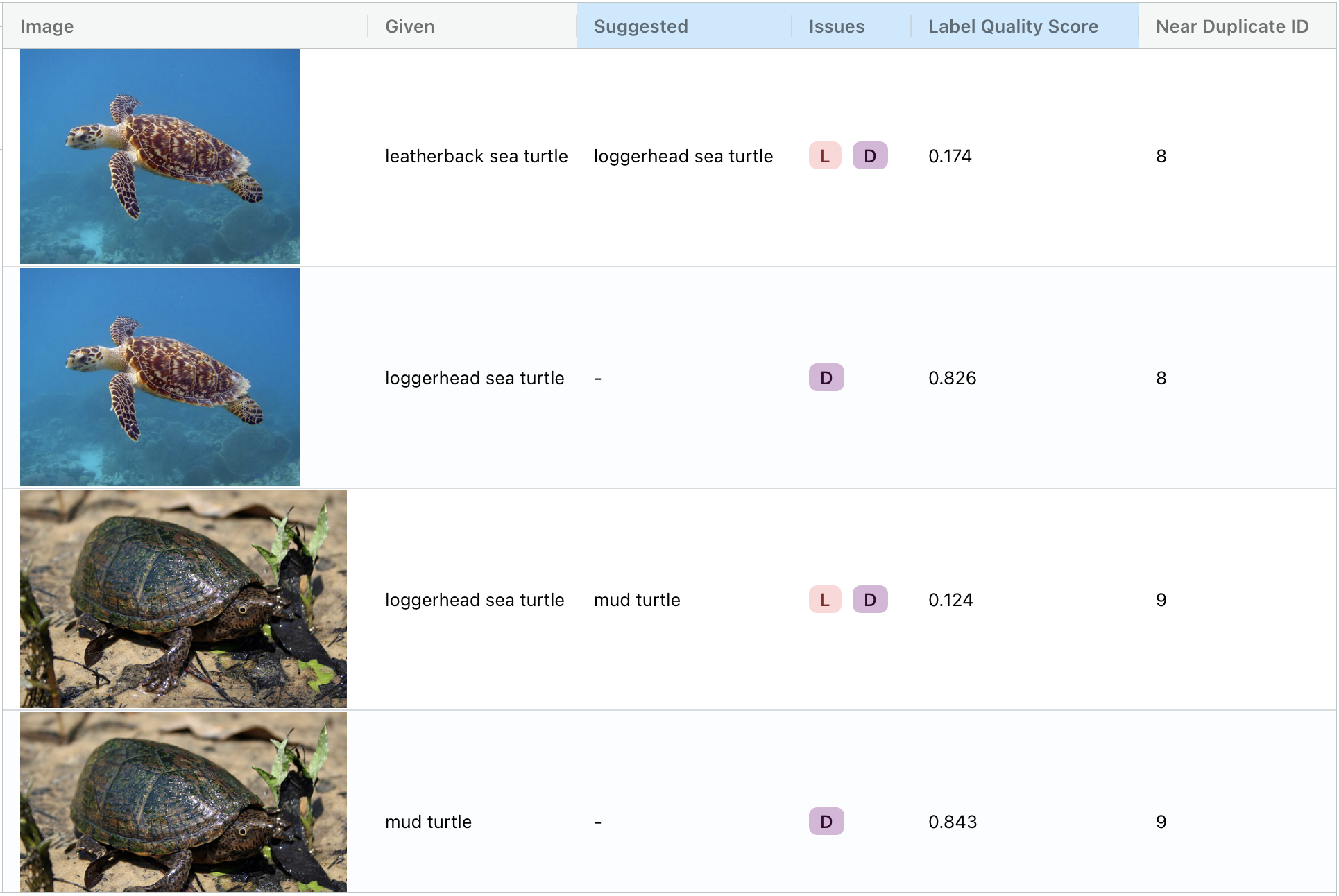
Cleanlab Studio is able to not only identify these duplicated images but also automatically identify the mislabeled image: for example, the first picture of a turtle is a loggerhead sea turtle, not a leatherback sea turtle. Such examples in a training set confuse a model during training; if these examples were in the test set, we’d be penalizing models that infer the correct label. In some cases, the same image even appears three times, in each case with a different label!
Fixing issues
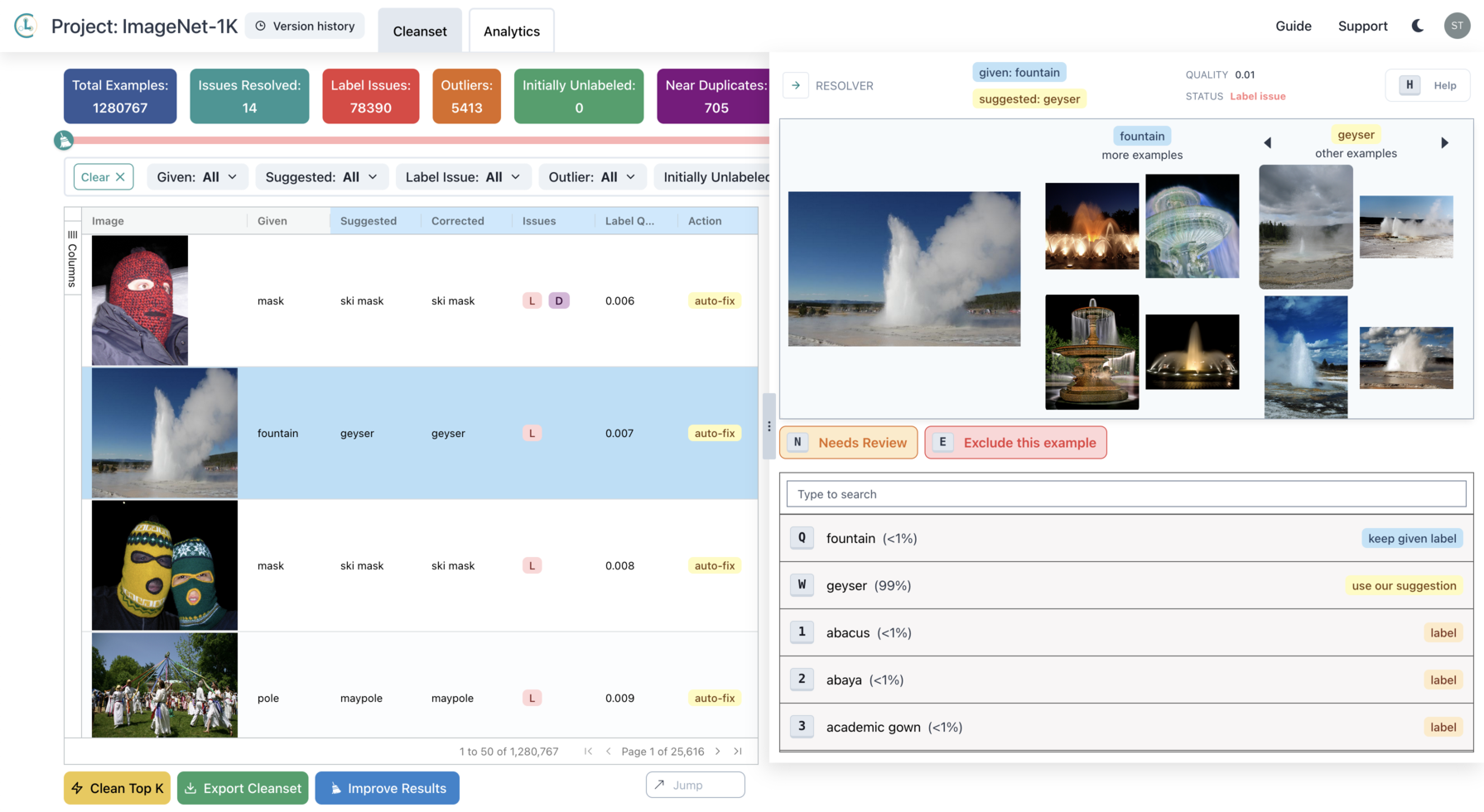
While this post focuses on finding issues in ImageNet, Cleanlab Studio can also be used to fix the issues. The app offers an intuitive interface for reviewing individual data points and issues (along with our suggestions for how to fix them):
Cleanlab Studio also supports a combination of filters and the ability to correct multiple data points at once. For example, we can find all the data points labeled “shoe store” but predicted to have a label issue and automatically fix all 55 of them at once:
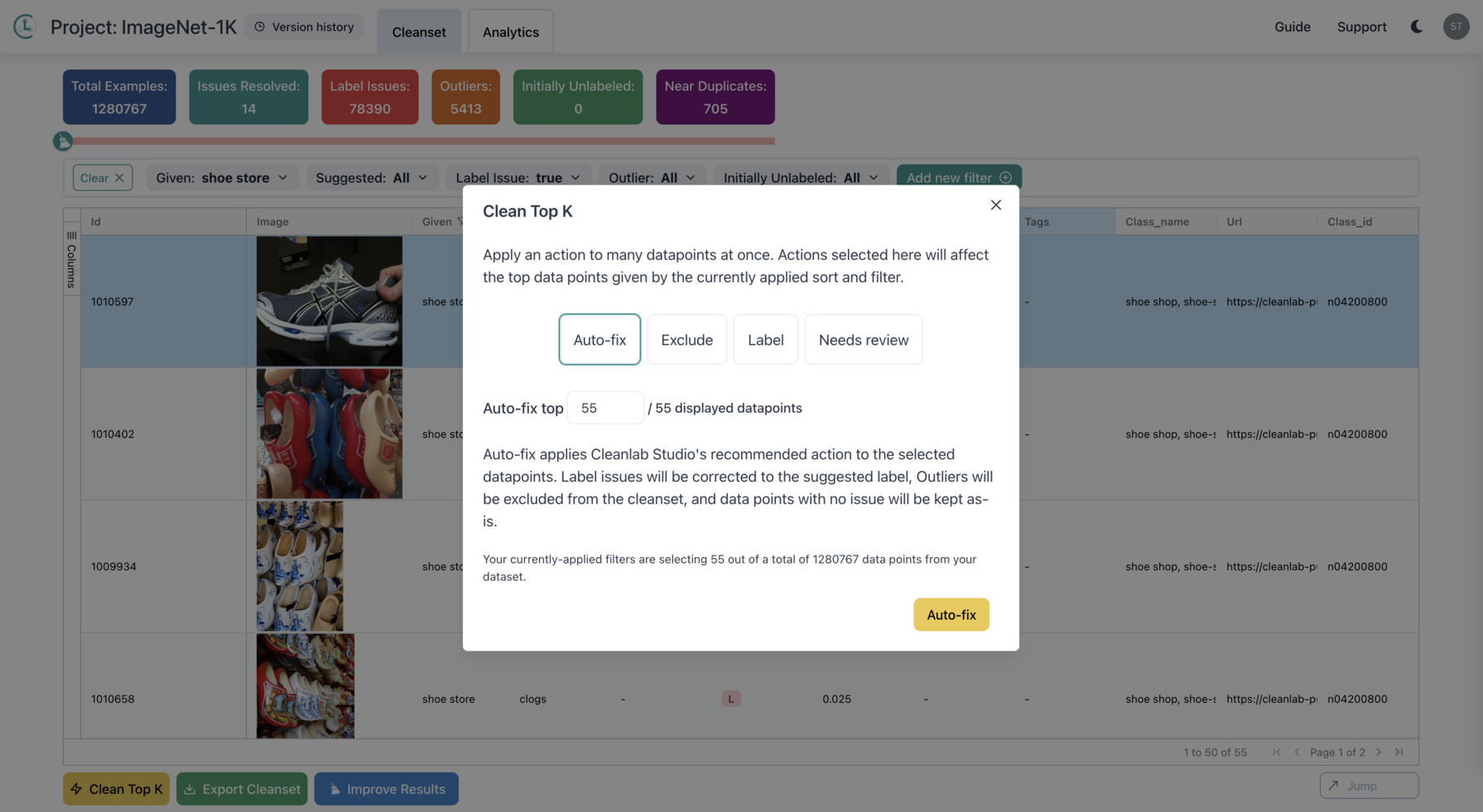
Conclusion
As shown in this post, even gold-standard academic datasets like ImageNet can be full of erroneous examples and dataset-level issues. As we’ve written about before, fixing data can have a huge impact on the performance of downstream applications like data analytics and machine learning. Data-centric AI tools like Cleanlab Studio can help you efficiently turn unreliable real-world data into reliable models and insights.
Resources
- Improve your data and models for free with Cleanlab Studio
- Learn how to improve accuracy and reduce time spent training ML models and deploying them to production; reach out to us at sales@cleanlab.ai
- Access advanced functionality, including support for ML tasks not supported in the publicly-available version, by signing up for Cleanlab Studio for Enterprise