

Letter from the CEO: Announcing Our Seed Funding and the Launch of Cleanlab Studio for Enterprise
 Curtis Northcutt
Curtis Northcutt
I am ecstatic to announce: Cleanlab’s flagship product, Cleanlab Studio for Enterprise is officially launching with $5 million in seed funding from Bain Capital Ventures, alongside angel investors including AME Cloud Ventures, Kearney Jackson, Essence VC, Naveen Rao of MosaicML, Freddy Kerrest of Okta, Chuck Dietrich of OpNet, and Avid Duggan of OpNet. (Business Wire Exclusive | VentureBeat Exclusive)
Cleanlab reduces 80-90% of the time and cost needed for teams to deploy data-driven AI solutions like LLMs, ML models, and business intelligence analytics that work more reliably and more accurately on real-world, messy datasets. Our products work by automatically improving and adding smart meta-data to every data point going in and every prediction coming out.
Since our PhD days at MIT, my co-founders and I spent a decade pioneering the pieces needed to create the world’s most advanced end-to-end solution for easily training and deploying a more accurate model or analytics system built on unreliable, real-world unstructured (visual, text, etc) and structured (Excel, csv, json, tabular, etc) datasets.


The Cleanlab Team. Working with this one-of-a-kind team is the one of the best parts of my job.
The most important problem for the future of AI is reliability
Prior to Cleanlab, I spent time at Microsoft (2014), Facebook AI Research (2016), Amazon Alexa (2017), Oculus Research/Meta (2018), and Google AI (2019) and I discovered a pattern… they all struggled with the same problem: no automated solution exists to help teams and enterprises automate handling problematic data and its impact on AI and analytics solutions.


Over the last decade, I saw the future of AI limited by the same problem over and over: the need for an end-to-end enterprise solution for automating data curation for LLMs, ML, and analytics.
There is nothing like the feeling when you first discover something undiscovered — I felt that feeling when I first discovered how to find incorrect values in any ML dataset without human intervention. The first person I shared my discovery with back in 2016 was Jonas Mueller, now the Chief Scientist and Co-Founder of the company built on that discovery. When it was time to scale the work to all datasets, I asked the smartest person I knew in computer systems at MIT for help — Anish Athalye, now the CTO and Co-Founder of Cleanlab. Prior to Cleanlab, Jonas built Amazon’s auto-ML layer used by AWS today and Anish grew a massive open-source following of 30k+ stars for his open-source tools. By coupling my PhD work to auto-improve datasets, Jonas's work to auto-improve ML models, and Anish's work to build and scale secure systems, our team is uniquely positioned to achieve Cleanlab’s mission to make artificial intelligence more accessible and effective.
Announcing Cleanlab Studio for Enterprise
Pioneered at MIT, rooted in open-source, proven by Fortune-500 companies, today we officially launch Cleanlab Studio for Enterprise.
Using Cleanlab Studio, enterprise teams get more value out of their data by automating the process of finding and fixing outliers, label issues, and other data issues in image, text, and tabular datasets, enabling them to train more reliable models and derive more accurate analytics and insights. Unlike other solutions in this space, Cleanlab Studio handles model training for you with state-of-the-art auto-ML, requires no hyper-parameter tuning or model selection, no code, and no machine learning expertise to deliver an improved dataset, ML model, and business insights in significantly less time.

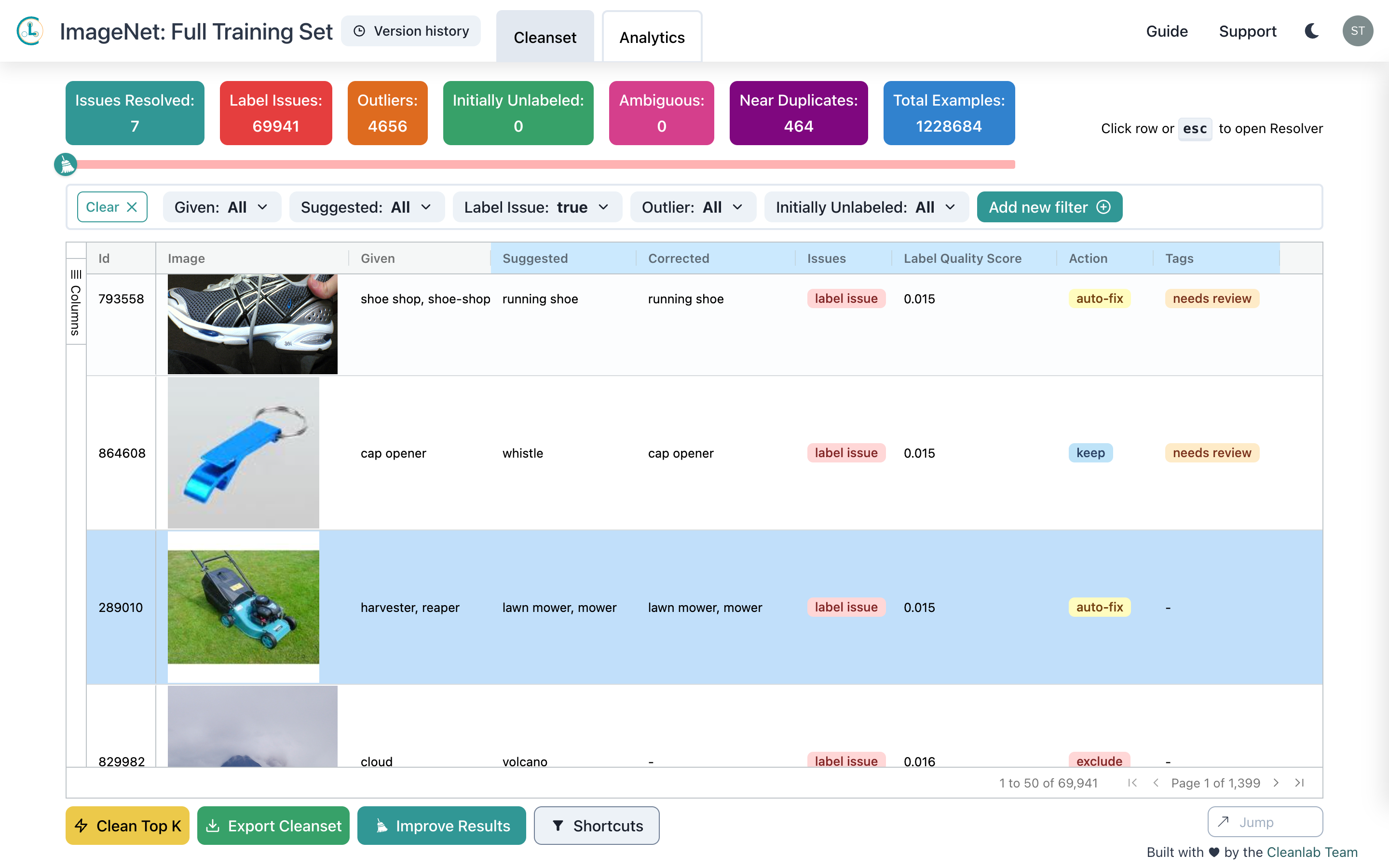
Example of Cleanlab Studio automatically finding and fixing outliers, label issues, duplicates, and more in a ~1 million image dataset. Cleanlab Studio works similarly for text and tabular datasets.
BBVA, one of the largest financial institutions in the world, reduced their AI labeling costs by more than 98% and improved the reliability of their ML model accuracy by 28% using Cleanlab. Imagine spending $20k instead of $1M.
“Cleanlab helped us reduce the uncertainty of noise in the tags. This process enabled us to train the model, update the training set, and optimize its performance. The goal was to reduce the number of labeled transactions and make the model more efficient, requiring less time and dedication. With the current model, we were able to improve accuracy by 28%, while reducing the number of labeled transactions required to train the model by more than 98%.”
— David Muelas Recuenco, Expert Data Scientist at BBVA
Google used Cleanlab to find and fix label errors in millions of speech samples across different languages, to quantify annotator accuracy, and provide clean data for training speech models.
“Cleanlab is well-designed, scalable and theoretically grounded: it accurately finds data errors, even on well-known and established datasets. After using it for a successful pilot project at Google, Cleanlab is now one of my go-to libraries for dataset cleanup.”
— Patrick Violette, Senior Software Engineer at Google
Amazon AWS Principal Solutions Architect Cher Simon shares how she uses Cleanlab to train better models in less time. Learn more about how Amazon uses Cleanlab to improve the Alexa customer experience here.
“Manually inspecting and fixing potential label errors can be time-consuming. We can train a better model using Cleanlab to filter noisy data.”
— Cher Simon, Amazon AWS Principal Solutions Architect at Amazon
The Privilege to Work with a World-class Team
I am honored to work with a world-class team and our incredible partners at Bain Capital Ventures. I believe wholeheartedly that I have the two best Co-Founders in the world, Jonas Mueller and Anish Athalye, and I am reminded daily why it is a privilege to work with two of the smartest people I know who also happen to be two of my best friends.
The caliber of our founding team is a humbling reminder that we must use our roles at Cleanlab to create something good for the world. The privilege to work together is a rare opportunity. We must be sure not to do less than anyone else would if they had the same opportunity.
FAQ
What do I get with the Enterprise version of Cleanlab Studio?


To try out Cleanlab Studio, sign-up here: https://cleanlab.ai/sales.
How does Cleanlab Studio differ from Cleanlab open-source?
Cleanlab open-source finds issues, it doesn’t fix them. Correcting a dataset requires an interface to visualize and choose which subsets of the data to correct for the most accurate performance. Cleanlab Studio provides the interface, state-of-the-art LLMs and ML models trained for you automatically, model deployment with an improved ML model in a single-click. The open-source is the doctor who helps you find out what’s wrong. For treatment or surgery, you’ll need Cleanlab Studio.
Does Cleanlab improve fine-tuning and output reliability for LLMs? (Yes!)
- How to improve LLMs on Databricks with Cleanlab:
- How to improve LLM fine-tuning accuracy by 30% using Cleanlab:
- How to train LLMs in 1/3 the time/cost:
- How Cleanlab finds errors in Anthropics RLHF LLM dataset:
- How Cleanlab improves reliability in Prompt Selection:
- How to ensure reliable few-shot prompt selection for LLMs:

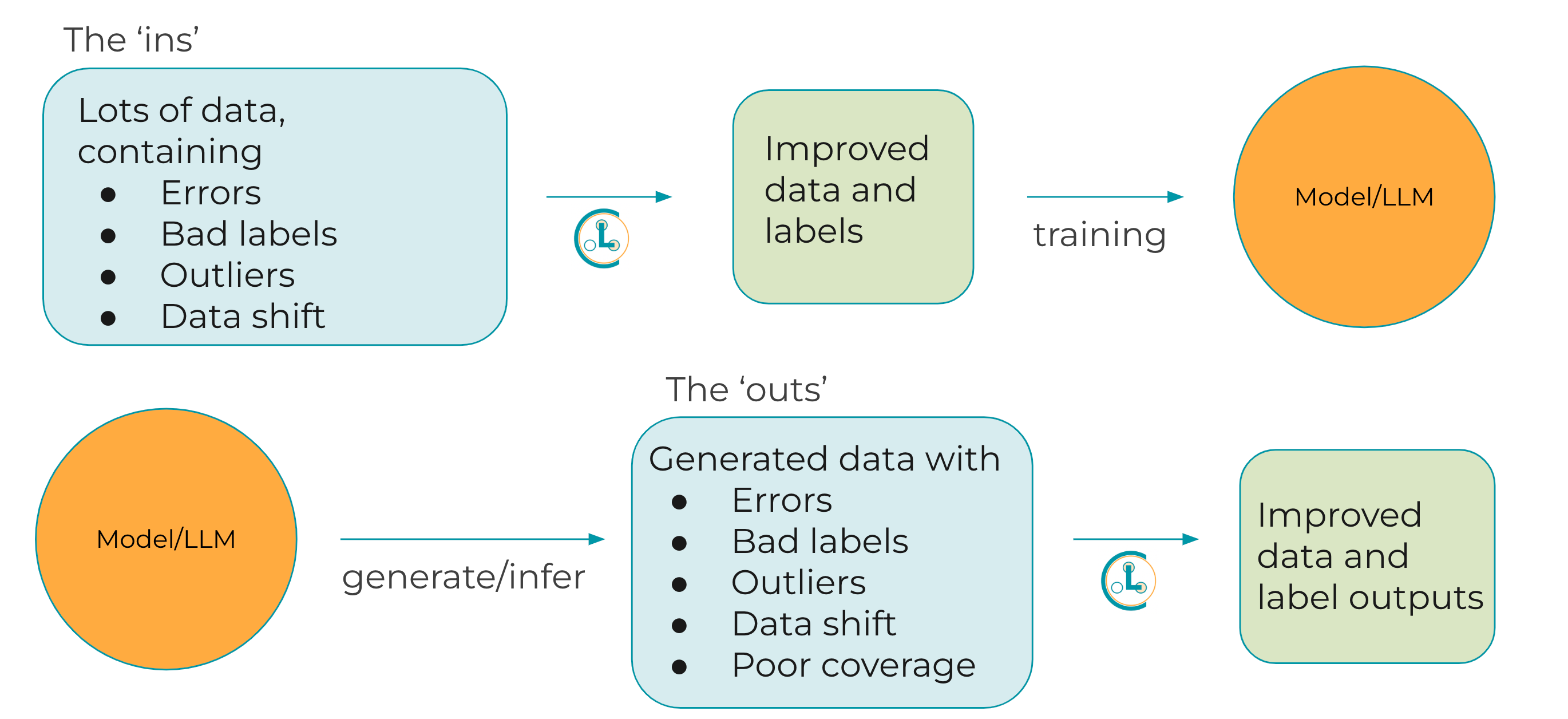
A simplified visualization showing how Cleanlab improves fine-tuning LLMs (top) and controls for reliability of outputs of downloaded open-source LLMs (bottom).
Dive Deeper
Learn more about Cleanlab:
- Cleanlab Studio
- Blog and Publications
- Our Culture and Our (Amazing) Team
- Slack community
- Careers at Cleanlab
