

ActiveLab: Active Learning with Data Re-Labeling
 Hui Wen Goh
Hui Wen Goh  Jonas Mueller
Jonas Mueller
Labeled data is key to training supervised Machine Learning models, but data annotators often make mistakes. To mitigate annotation mistakes, one can collect multiple annotations per datapoint to determine a more reliable consensus label, but this can be expensive! To train the best ML model with the least data labeling, a key question is: which new data should I label or which of my current labels should be checked again?
We’ve open-sourced ActiveLab, a novel active learning method we just published, that helps you decide which data should be labeled next or re-labeled again to maximally improve your ML model within a limited annotation budget. Under a fixed total number of allowed annotations, training datasets constructed with ActiveLab lead to much better ML models vs. other active learning methods. The below figure shows this on the (tabular) Wall Robot classification dataset:

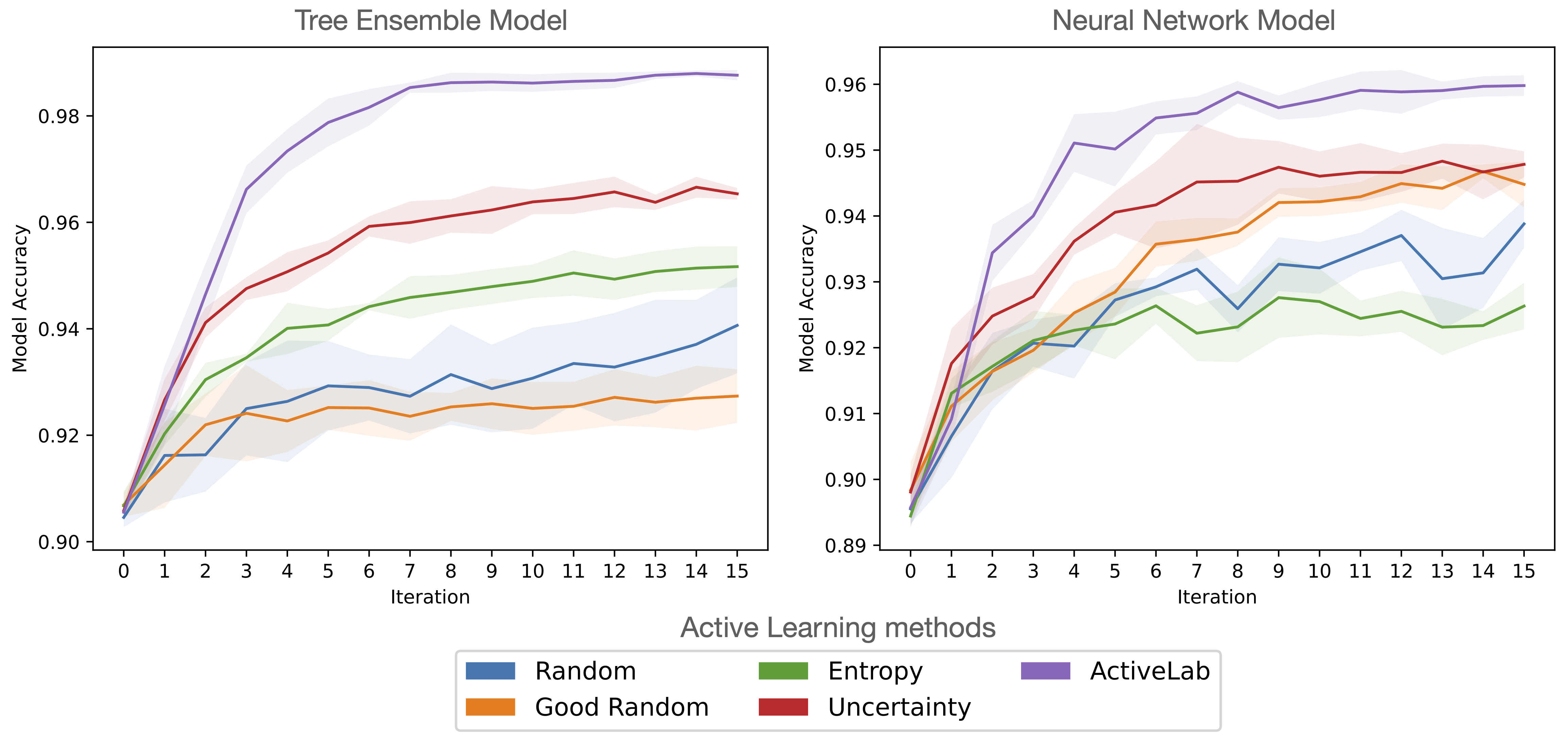
Here we start with an initial training set of 500 labeled examples. We train a classifier model for multiple rounds, plotting its test accuracy after each of these iterations (ExtraTrees model on left, MLP model on right). In each round, we collect additional annotations for 100 examples, chosen from either this set of 500, or a separate pool of 1500 initially-unlabeled examples. We use various active learning methods to decide which data to label/re-label next. At the end of each round, we train a new copy of our model with consensus labels established from the currently-annotated data. Random corresponds to random selection of which examples to collect an additional annotation for; Good Random randomly selects amongst the examples with the fewest annotations so far (prioritizing the unlabeled data first); Entropy and Uncertainty are popular model-based active learning methods that base the selection on a model’s probabilistic predictions. ActiveLab also relies on these predictions to estimate how informative another label will be for each example, but our method additionally accounts for: how many annotations an example has received so far and their agreement, and how trustworthy each annotator is overall relative to the trained model.
Similar results hold for other models as well as image classification datasets, as shown in our paper which details the research that went into developing this method:
ActiveLab: Active Learning with Re-Labeling by Multiple Annotators
Our paper extensively benchmarks ActiveLab against more active learning methods in multi-annotator and single-annotator settings, and contains more details about the above figure plus many others that show ActiveLab trains better classifiers than other data (re)labeling strategies.
How do I use ActiveLab?
Our tutorial notebook shows how a single line of Python code can produce ActiveLab scores for each datapoint (irrespective of whether it is already labeled or not). Lower scores indicate datapoints for which collecting one additional label should be most informative for our current model. Open-sourced as part of the cleanlab library, ActiveLab just requires the following inputs:
- Dataset labels stored as matrix
multiannotator_labelswhose rows correspond to the examples that have at least one annotation, columns to each annotator’s chosen labels (NArepresenting missing annotations for examples that a particular annotator did not label). - Predicted class probabilities
pred_probsfrom any trained classifier for these examples, as well as additionalpred_probs_unlabeledfor a separate pool of unlabeled examples (from the same classifier).
from cleanlab.multiannotator import get_active_learning_scores
scores_labeled, scores_unlabeled = get_active_learning_scores(
multiannotator_labels, pred_probs, pred_probs_unlabeled
)The scores returned by this code are directly comparable between the labeled/unlabeled data! If you want to collect additional annotations to best improve your dataset before model re-training, you should ask annotators to label the examples with the lowest scores (regardless of how many annotations each example already has).
After data has been labeled in this manner, a natural question is: how good is each annotator overall? With another line of code, you can use CROWDLAB to accurately estimate this based on the annotations collected so far.
from cleanlab.multiannotator import get_label_quality_multiannotator
quality_estimates = get_label_quality_multiannotator(
multiannotator_labels, pred_probs
)How does it work?
ActiveLab helps answer the key question: when is it better to collect one more label for a previously-annotated datapoint vs. a label for a brand new example from the unlabeled pool? The answer depends on how reliable we think the currently-collected annotations are. Intutively, we might get another opinion for examples with only a single annotation from an unreliable annotator, or for examples with two annotations that do not agree. Such relabeling is particularly important when the harms of training a model with mislabeled data cannot be mitigated by simply labeling new datapoints from the unlabeled pool.
Some of the most accurate ML predictions are produced via weighted ensembling of the outputs from different individual predictors. CROWDLAB is a method to estimate our confidence in a consensus label from multi-annotator data, which produces accurate estimates via a weighted ensemble of any trained model’s probabilistic prediction and the individual labels assigned by each annotator . ActiveLab forms a similar weighted ensemble estimate, treating each annotator’s selection as a probabilistic decision output by another predictor:
Here if annotator did not label a particular example, is the weight of the average annotator, and denotes the number of classes in our dataset. Weights are assigned according to an estimate of how trustworthy the model is vs. each individual annotator.
Intuitively, the weighted ensemble prediction for a particular example becomes more heavily influenced by the annotators the more of them have labeled this example, and the resulting probabilities will be more confident if these annotators agree. Such examples are those that will be least informative to collect another label for. Beyond the number of annotations and their agreement, the ActiveLab estimate accounts for: how confident the model is, and how often annotators make mistakes vs. the model. The latter is estimated via the weights above, which allow ActiveLab to still perform effectively even when the classifier is suboptimally-trained or some annotators often give incorrect labels.
ActiveLab decides to re-label data when the probability of the current consensus label for a previously-annotated datapoint falls below our (purely model-based) confidence in the predicted label for an un-annotated datapoint. ActiveLab estimates the utility of collecting another label to further improve consensus labels and models trained therewith. It relies on the term in its weighted ensemble above, unlike CROWDLAB, which estimates the likelihood that a consensus label is correct or not (and is just for analyzing a static multi-annotator dataset). CROWDLAB assigns extremely low quality scores to examples annotated by many labelers that all disagree, whereas ActiveLab recognizes there may be less utility in collecting one more label for such fundamentally difficult examples (vs. examples that currently have fewer annotations).
All the fun mathematical details can be found in our paper.
Should I ever relabel data when there is infinite unlabeled data?
In most settings, there is a limited pool of unlabeled data that annotators can consider labeling. But if we had infinite amounts of such data, should we always prefer to label entirely new examples instead of sometimes re-labeling? If our annotators are perfectly reliable, then the answer is yes. But what if annotators make mistakes, as is typical in practice?
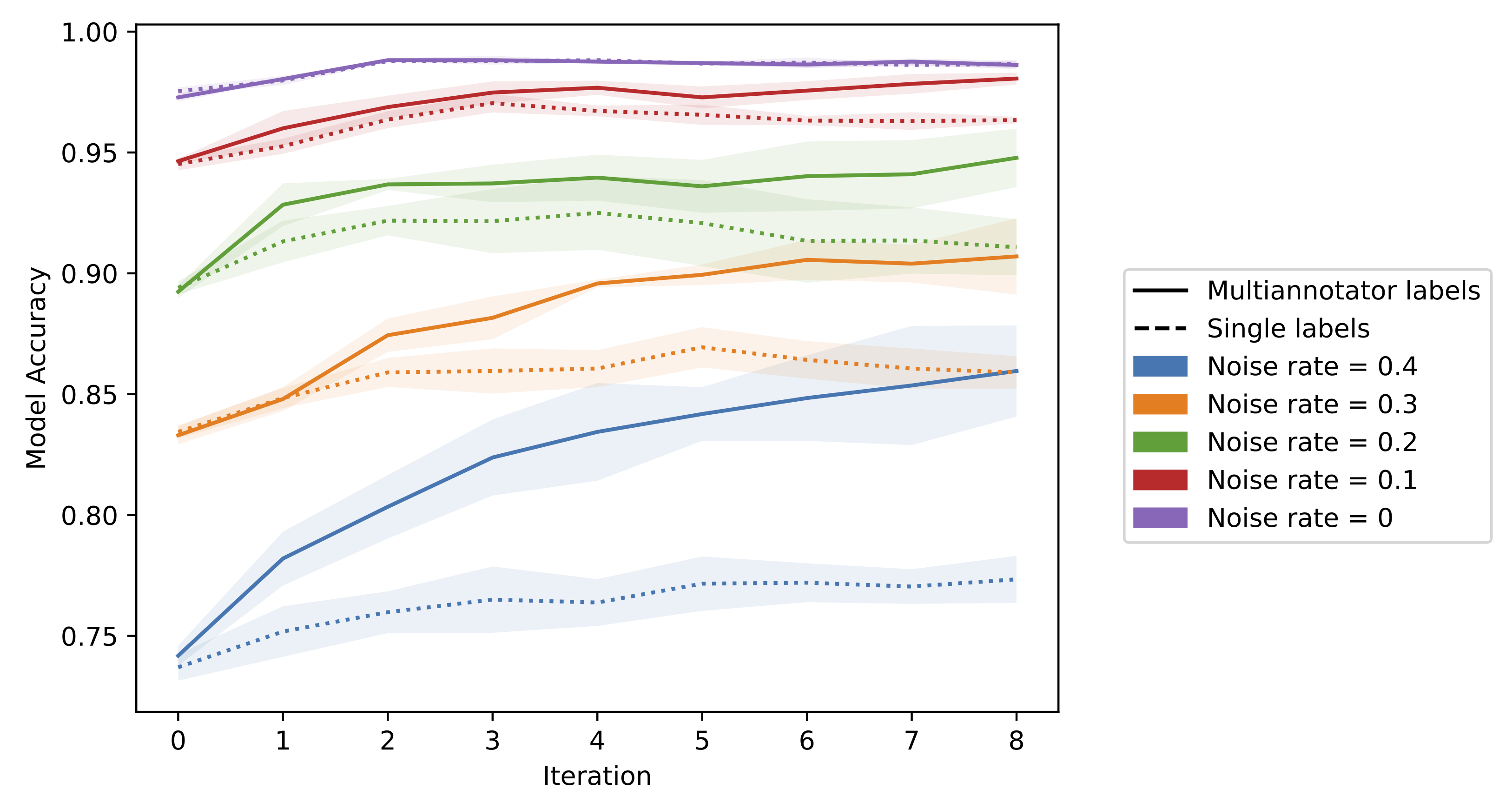
The figure above shows a comparison of these two alternatives on a variant of the Wall Robot dataset, where we simulate annotators with different labeling noise rates. Here we iteratively train a tree ensemble classifier either via ActiveLab with re-labeling allowed, or active learning with the traditional entropy score that only considers labeling examples from the currently unlabeled pool (at most one label per example, with a large unlabeled pool).
When annotators provide noisy labels, there are clear benefits of re-labeling data to get higher quality consensus labels, even when there exists infinite amounts of unlabeled data that could be labeled instead.
What about traditional (single-annotation) active learning?
The code to use ActiveLab presented above is also useful for traditional active learning settings where we collect at most one annotation per example (e.g. if we know the labels are trustworthy). In such settings, you can simply ignore the ActiveLab scores for previously-annotated data. In this case, ActiveLab becomes equivalent to Uncertainty-based active learning, which scores examples based on the confidence the model has in its predictions.
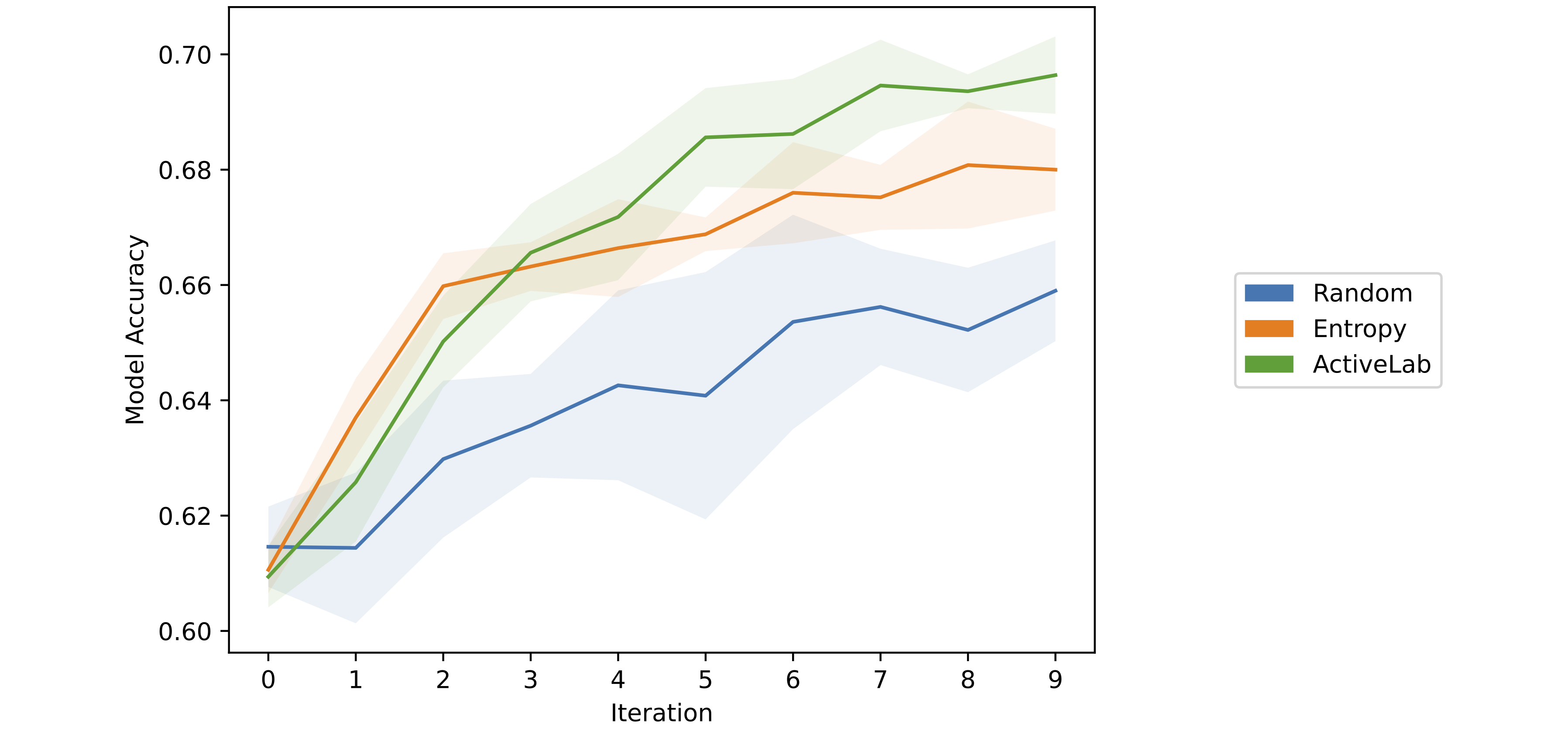
The figure above compares ActiveLab (i.e. uncertainty-based active learning) against two other methods in the single-annotation setting: Entropy-based active learning which is quite similar, and Random-selection of which example to annotate next. These results are again for training a tree ensemble classifier on increasingly-sized labeled subsets of the Wall Robot dataset.
Labeling data via ActiveLab remains far superior than random selection, even when there is only a single annotator who never reviews previous annotations.
What if there is no unlabeled data? (Label Cleaning)
ActiveLab can also improve the consensus labels of a dataset where every example already starts with at least one annotation, and we only want annotators to review previously-labeled data. This setting can be viewed as iterative Label Cleaning. Nothing needs to change from the code presented above to apply ActiveLab in this setting; there is simply no unlabeled data to score, and we still choose the examples with the lowest ActiveLab scores to collect additional labels for.
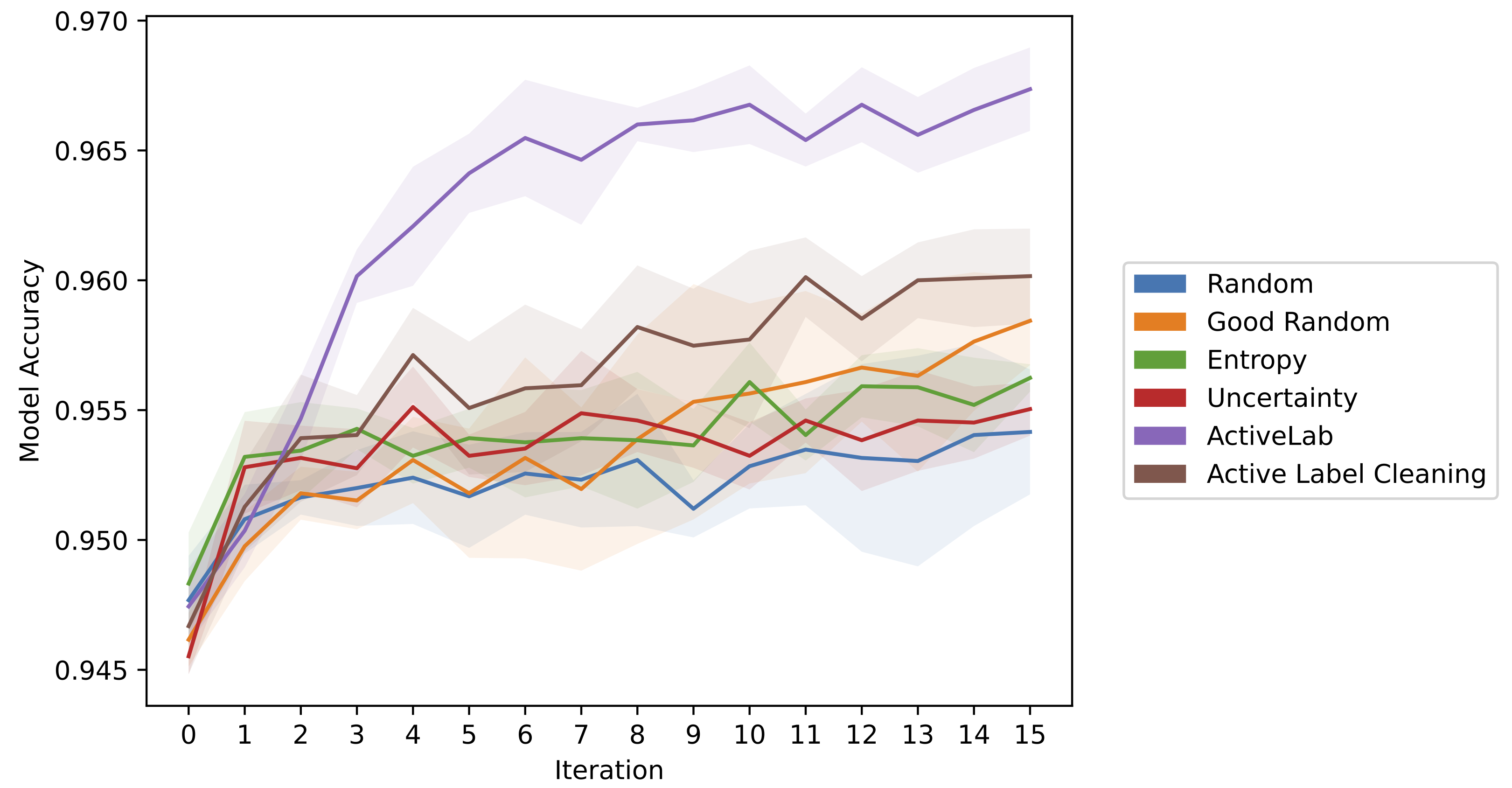
The figure above compares various methods for label cleaning, where we only collect additional labels in each round for data that starts off as annotated. In each round, we train a tree ensemble classifier on consensus labels established from the annotations collected thus far for the Wall Robot dataset, and then report its test accuracy.
In this setting, ActiveLab produces better consensus labels from 5x fewer total annotations than recent methods specifically designed for Active Label Cleaning. By appropriately harnessing multiple annotators to review each other’s labels, such methods signficantly outperform traditional active learning scores in this setting.
Note: ActiveLab never imposes any requirements on which annotator should label which examples. You can send all examples with the lowest ActiveLab scores to a single new annotator, or distribute them amongst previously-used annotators as is most convenient.
Resources to learn more
- Tutorial on using ActiveLab to efficiently label your own data and train an effective model
- ActiveLab paper containing all the mathematical details and extensive comparisons against other methods
- Code to reproduce our active learning benchmarks
- cleanlab open-source library
- Cleanlab Studio: no-code data improvement
Join our community of scientists/engineers to ask questions, see how others used ActiveLab, and help build the future of open-source Data-Centric AI: Cleanlab Slack Community